Вредоносное ПО (malware) - это назойливые или опасные программы,...


Для выполнения своих основных функций по работе с реляционными таблицами язык SQL имеет достаточно богатый и сложный набор команд. Для лучшего понимания все команды языка разбиты на «уровни». В одной из классификаций, предусмотренных стандартом SQL, этот язык разбивается на «базовый», «промежуточный» и «полный» уровни.
Остановимся только на базовом уровне, содержащем около сорока команд. В таблице приводится подмножество команд базового уровня языка SQL.
| Команда | Назначение |
| Команды определения данных | |
| CREATE TABLE | Создает структуру таблицы |
| DROP TABLE | Удаляет таблицу |
| ALTER TABLE | Изменяет описание структуры таблицы |
| CREATE VIEW | Создает представление |
| INSERT | Добавляет новые записи в таблицу |
| DELETE | Удаляет записи из таблицы |
| UPDATE | Обновляет данные таблицы |
| Команда извлечения данных | |
| SELECT | Извлекает данные из базы данных |
| COMMIT | Сообщает об успешном окончании транзакции |
| ROLLBACK | Сообщает о неуспешном окончании транзакции |
| Команды управления доступом | |
| GRANT | Предоставляет пользователю определенные права доступа |
| REVOKE | Отменяет определенные права доступа |
| Команды встроенного SQL | |
| DECLARE, OPEN, FETCH, CLOSE | Реализуют обращения к базе данных из прикладных программ. |
Команды определения данных служат для создания и удаления таблиц, а также изменения структуры таблицы, например, для добавления нового поля. С помощью команды CREATE VIEW создается представление , т.е. таблица содержащая данные из других таблиц.
Команды манипулирования данными позволяют изменять данные в реляционной таблице, но не меняют ее структуру.
Команды управления транзакциями позволяют обеспечить целостность базы данных.
SQL-транзакция – это несколько последовательных команд SQL, которые должны выполняться как единое целое.
Транзакция либо успешно выполняется, и тогда СУБД фиксирует произведенные изменения базы данных, на внешнем носителе; либо отменяется, и тогда все произведенные изменения СУБД ликвидирует. Таким образом, принцип транзакции «либо все, либо ничего». Примером транзакции может служить перевод денег клиентом банка из одного филиала в другой. Необходимо как единое целое осуществить два действия: списать деньги со счета в одном филиале и занести деньги на счет в другом филиале.
Вязыке SQL обработка транзакций реализована с помощью двух команд – COMMIT и ROLLBACK. Они управляют изменениями, выполненными группой команд. Команда COMMIT сообщает об успешном окончании транзакции. Она информирует СУБД о том, что транзакция завершена, все ее команды выполнены успешно и противоречия в базе данных не возникли. Команда ROLLBACK сообщает о неуспешном окончании транзакции. Она информирует СУБД о том, что пользователь не хочет завершать транзакцию, и СУБД должна отменить все изменения, внесенные в базу данных в результате выполнения транзакции. В этом случае СУБД возвращает базу данных в состояние, в котором она находилась до выполнения транзакции.
Команды COMMIT и ROLLBACK используются в основном в программном режиме, хотя возможно их использование и в интерактивном режиме.
К командам управления доступом относятся команды для осуществления административных функций, присваивающих или отменяющих право (привилегию) использовать таблицы базы данных определенным образом. Каждый пользователь базы данных имеет определенные права по отношению к объектам базы.
Права – это те действия с объектом, которые может выполнять пользователь. Права могут меняться с течением времени: старые могут отменяться, новые – добавляться. Предусмотрены следующие права:
· INSERT – право добавлять данные в таблицу;
· UPDATE – право изменять данные таблицы;
· DELETE – право удалять данные из таблицы;
· REFERENCES – право определять первичный ключ.
Пользователь, создавший таблицу, является ее владельцем. Как владелец, пользователь имеет все права на таблицу и может назначить права для работы с ней другим пользователям. Кроме владельца, права может назначать администратор базы данных.
К встроенным относятся команды, предназначенные для реализации обращения к базе данных из прикладных программ, написанных на определенном языке программирования. Для пересылки данных из базы данных в прикладную программу используется временная таблица, называемая SQL-курсором . Команды DECLARE, OPEN, FETCH, CLOSE позволяют управлять SQL-курсором.
Знания и их виды.
В мировой экономике успешность бизнеса в последнее время определяется не только материальными, но и нематериальными факторам, особое место среди которых занимают «знания». Если раньше стоимость компаний составляли финансовый капитал, здания, оборудование и другие материальные ценности, то в новой, информационной эпохе, главным источником богатства становится интеллектуальный капитал – систематизированные и уникальные знания.
Знания – это единственный ресурс, который не поддается быстрому воспроизводству конкурентами, что позволяет компании, владеющими ими, получать уникальные преимущества.
В общем случае существует много определений знаний. Некоторые из них приведены ниже:
Знание - это форма существования и систематизации результатов познавательной деятельности человека.
Знание - субъективный образ объективной реальности, то есть адекватное отражение внешнего и внутреннего мира в сознании человека в форме представлений, понятий, суждений, теорий.
Знание в широком смысле - совокупность понятий, теоретических построений и представлений.
Знание в узком смысле - данные, информация.
Знание (предмета) - уверенное понимание предмета, умение самостоятельно обращаться с ним, разбираться в нём, а также использовать для достижения намеченных целей.
Данные – не подвергшиеся обработке сведения, факты, измерения, сигналы, имеющие отношение к событиям. Они являются «сырым» материалом для дальнейших преобразований.
Информация – совокупность фактов, явлений, событий, представляющий интерес, подлежащих регистрации и обработке. Другими словами- это обработаны, осмысленные данные
Знания -информация (у индивидуума, общества или у системы искусственного интеллекта) о мире, включающих в себя информацию о свойствах объектов, закономерностях процессов и явлений, а также правилах использования этой информации для принятия решений. Правила использования включают систему причинно-следственных связей. Знания дают ответ на вопрос «Как?».
Мудрость - оценка понимания знаний, правильное применение накопленных знаний, учитывая реалии и ограничений . Мудрость дает ответ на вопрос «Почему?».
Классификация видов и форм знания в настоящее время является во многом дискуссионной. Приведем некоторые виды.
Знания могут быть:
декларативные
процедурные
Декларативные знания содержат в себе лишь представление о структуре неких понятий. Эти знания приближены к данным, фактам. Например: высшее учебное заведение есть совокупность факультетов, а каждый факультет в свою очередь есть совокупность кафедр.
Процедурные знания имеют активную природу. Они определяют представления о средствах и путях получения новых знаний, проверки знаний. Это алгоритмы разного рода. Например: знания, полученные в результате мозгового штурма или компьютерные программы. Процедурные знания дают представления о средствах и путях получения новых знаний, проверки знаний. Они имеют активную природу.
Знания могут быть
научными
вненаучными.
Научные знания могут быть
эмпирическими (на основе опыта или наблюдения)
теоретическими (на основе анализа абстрактных моделей).
Вненаучные знания могут быть:
паранаучными - знания несовместимые с имеющимся познавательным стандартом стандартом. Широкий класс паранаучного (пара от греч. - около, при) знания включает в себя учения или размышления о феноменах, объяснение которых не является убедительным с точки зрения критериев научности;
антинаучными - как утопичные и сознательно искажающие представления о действительности. Приставка «анти» обращает внимание на то, что предмет и способы исследования противоположны науке. С ним связывают извечную потребность в обнаружении общего легко доступного «лекарства от всех болезней». Особый интерес и тяга к антинауке возникает в периоды социальной нестабильности.
псевдонаучными - представляют собой интеллектуальную активность, спекулирующую на совокупности популярных теорий, например, истории о древних астронавтах, о снежном человеке, о чудовище из озера Лох-Несс;
обыденно-практическими - доставлявшими элементарные сведения о природе и окружающей действительности. Люди, как правило, располагают большим объемом обыденного знания. Обыденное знание включает в себя и здравый смысл, и приметы, и назидания, и рецепты, и личный опыт, и традиции. Оно хотя и фиксирует истину, но делает это не систематично и бездоказательно. Его особенностью является то, что оно используется человеком практически неосознанно и в своем применении не требует предварительных систем доказательств.
личностными- зависящими от способностей того или иного субъекта и от особенностей его интеллектуальной познавательной деятельности.
Знания могут быть
неявные, (скрытые) знания
формализованные (явные) знания;
Неявные знания:
знания людей,
Формализованные (явные) знания:
знания в документах,
знания на компакт дисках,
знания в персональных компьютерах,
знания в Интернете и др.
Для эффективного управления предприятием необходимо организовать совместное использование знаний, их защиту и интеграцию в цепочку бизнес- процессов. Такая технология известна как управление знаниями (Knowledge Management).
Базы знаний.
База знаний - это один или несколько специальным образом организованных файлов, хранящих систематизированную совокупность понятий, правил и фактов, относящихся к некоторой предметной области.
Из определения видно, что в отличие от базы данных в базе знаний (БЗ) хранятся не только данные, описывающие рассматриваемую предметную область, но также и правила, описывающих целесообразные преобразования хранящихся данных.
База знаний является основным компонентом интеллектуальных систем: информационных, обучающих, систем программирования, а также экспертных систем.
Под экспертной системой (ЭС) понимается система, объединяющая возможности компьютера со знаниями и опытом эксперта в такой форме, что система может предложить разумный совет или осуществить разумное решение поставленной задачи. Дополнительно желаемой характеристикой такой системы является способность системы пояснять по требованию ход своих рассуждений в понятной для спрашивающего форме.
Общую структуру экспертной системы можно представить (Рис 9.2)
Рис. 18. Общая структура экспертной системы
Подсистема общения служит для ведения диалога с пользователем, в ходе которого ЭС запрашивает у пользователя необходимые факты для процесса рассуждения, а также, дающая возможность пользователю в какой-то степени контролировать и корректировать ход рассуждений экспертной системы.
Машина логического вывода - механизм рассуждений, оперирующий знаниями и данными с целью получения новых данных из знаний и других данных, имеющихся в рабочей памяти.
Язык SQLсчитают декларативным в отличие от языков на которых пишутся программы – это значит что язык SQL описывает что нужно сделать, а не каким образом. Существует две формы языка SQL:
· Интерактивный режим (используется для создания вопросов пользователя и получения результатов в интерактивном режиме).
· Встроенный режим (состоит из команд SQL встроенных внутрь программ написанных на другом языке программирования.)
Основу языка SQLсоставляют операторы, распределенные между 3 компонентами этого языка:
1. Язык манипулирования данными – предназначен для поддержки БД и включает операторы добавления, изменения, удаления и выборки данных.
2. Язык определения данных – предназначен для создания изменения, удаления таблиц и всей БД в целом.
3. Язык управления данных – предназначен для обеспечения защиты от различного рода повреждений (СУБД гарантирует некоторую защиту автоматически).
SQL относится к непроцедурным языкам программирования. В отличие от процедурных языков SQLориентирован не на записи, а на множество кортежей, т.е. входной информацией для выполнения запроса является множество кортежей одного или нескольких отношений. Также и в ходе выполнения запроса формируется множество кортежей удовлетворяющих некоторому условию, т.е. SQL задает непоследовательность действий необходимых для получения результата, а условие, которому должны соответствовать кортежи.
Ключевые слова в выражениях на SQL могут прописываться как строчными, так и прописным, и буквами в одну или несколько строк. Каждый запрос должен заканчиваться «;». Зарезервированные слова не могут использоваться в качестве названия объектов БД.
Выборка данных с использование предложения Select.
Selectсписок_столбцовfromимя_таблицы.
Select * from товар where prise< 50000;
В конструкции whereмогут применятся следующие операторы:
2. IsNULL – выбираются все строки не имеющие значения в указанном поле. select * fromTovarwheresrok_godisnull.
3. Between – позволяет проверить вхождение какого-либо значения в диапазон определяемый граничными значениями. select * fromTovarwherepricebetween 100000 and 1000000.
4. In – проверяет вхождение какого-либо значения в список значений. Список значений указывается в круглых скобках, значения перечисляются через запятую.select * fromTovarwhereprice in(20000, 30000, 50000).
5. Like – соответствие – просматривает строковые значения с целью определения входит ли заданная в операторе likeстрока в символьную строку проверяемого поля. select * fromTovarwherenamelike‘ирис’; в операторе Likeмогут использоваться следующие символы для указания шаблона искомой строки:
А) ? – замещает любой ОДИН символ
Б) * - допускает в указанном месте наличие любой последовательности символов.
Сортировка данных в таблице
Selectspisokfromimya_tabl orderbyимя_столбца . Если сортировка производится по нескольким столбцам, то их указываем через запятую. Ask – повозрастанию, desc – поубыванию. Select * fromTovarorderbyprice
Предложение groupby(группировать по) позволяет группировать записи в подмножество определяемые значением какого-либо поля и применять уже агрегирующие функции уже не ко всем записям функции, а к записям сформированной группы.
Selectсписок_столбцовfromимя_таблицыgroupbyстолбец_группировка.
Select avg (price) from Tovar group by kod_proiz;
Selectсписок_столбцовfromимя_таблицыgroupbyстолбец_группировкаhavingусловие; (группировка по условию).
Предложение havingопределяет критерии, по которому следует включать данные в группы. В условии, которое задается в предложение, havingуказывают только поля или выражение, которые на выходе имеют единственное значение для каждой выводимой группы.
Select avg (price) from Tovar group by kod_proizv having kod_proizv=1 or kod_proizv=2;
| Sportsman |
| Id |
| Fio |
| Pol |
| vozrASt |
| Club |
| sport |
Select fio, sport, club from sportsman;
Select * from sportsman where vozrast<18;
Select * from sportsman where pol like ‘ж*’;
Select * from sportsman where club like ‘спартак’;
Select * from sportsman where vozrast between 18 and 25;
Select avg(vozrast) from sportsman where sport like ‘волейбол’;
Select count(fio) from sportsman group by club;
Select * from sportsman where vozrast>25;
Select count(fio) from sportsman group by club having vozrast>25;
Вложенныезапросы
Select * from Tovar where kod_proiz in (select id from proizv where name like’А%’);
Select avg(price) from Tovar where kod_proiz in (select id from proizv where country like ‘Франция’);
Выполнение запросов во вложенном запросе начинается с наиболее вложенного, т.е. первый простейший запрос будет выполняться в последнюю очередь. Помимо вложенных запросов имеется другой способ объединения запросов при помощи оператора union в отличии от вложенных запросов union объединяет независимые запросы, т.е. они выполняются независимо друг от друга, а уже их вывод объединяется. Когда два или более запросов подвергаются объединению их столбцы вывода должны быть совместимы для объединения, т.е. каждый запрос должен указывать одинаковое количество столбцов, они должны быть перечислены в одинаковой последовательности и каждый должен иметь тип совместимый с каждым. Нельзя использовать union во вложенных запросах, а также нельзя использовать агрегирующие функции в запросах объединенных union.
Select name, price, kol from Tovar where price > 50000
select name, price,kol from Tovar where kod_proizv in (select id from proizv where country like ‘Франция’);
Манипулирование данными
К операторам манипулирования данными относятся вставка(insert), обновление (update) и удаление (delete).
Вставка записи.
Insertintoимя_таблицы[(поле1, … , полеn)] values (значение1, … , значение n);
Поля необязательно перечислять в запросе. Перечисление полей требуется только в том случае, если значение добавляется не во все поля таблицы.
Insert into Tovar values (1,’шоколад’, 100, 10500, ‘1 год’, 2);
Insertinto Tovar (id,name, price,kod_proizv values (2,”bhbc”,500,1));
Updateимя_таблицыsetзначения_столбца=значение ;
updateприменется ко всем записяи если нету where, если whereприсутствует то updasteприменяется к записям удовлетворяющим условиям.
Update Tovar set kol=kol+100;
Update Tovar set price=price*2 where kod_proizin(select id from proizvwhere country like ‘Франция’);
Delete from имя_таблицы;
Если условие отсутствует, то из таблицы удаляются все записи.
Delete from Tovar where srok_god is NULL;
Delete from proiz where license like ‘%2012’;
Организация данных в InterBase. Работа с доменами и таблицами.
Типы данных SQL:
Символьные типы данных:
1. char– один символ
2. char(n) –символьная строка фиксированной длины, где n – длина строки. Для хранения таких данных всегда отводится n байт вне зависимости от реальной длины.
3. varchar(n) – символьная строка переменной длины, для хранения данных этого типа отводится число байт соответствующее реальной длине строки.
Целочисленные данные:
1.integer/int – (-2147483647 - +2147483648) для хранения целочисленных данных отводится, как правило, 4 байта с указанным диапазоном значений.
2. smallint – (-32767 - +32768) короткое целое для хранения которого отводится 2 байта.
Вещественные типы данны:
1. float- вещественный тип данных для хранения которого отводится 8 байт.
2. smallfloat – для хранения данных отводится 4 байта.
4. decimal(p,n)–аналогичен floatр – количество значащих цифр, n – количество цифр после запятой.
Денежные типы данных:
1.money(p,n) – аналогичен типу данных decimal(p,n).Вводится только потому в некоторых СУБД, что для него используют специальные методы форматирования.
Дата и время:
1. date – для хранения даты.
2. time – для хранения времени.
3. interval – для хранения временного интервала.
4. datetime – для хранения моментов времени (год, месяц, число, часы, минуты, секунды, доли секунд).
Двоичные типы данных – позволяет хранить данные любого объема в двоичном коде:
Для всех типов данных имеется одно общее значение NULL, т.е. значение не определено. Это значение имеет каждый элемент столбца, пока в него не будут внесены данные.
Создание БД при помощи SQL запросов.
Create database имя_БД;
Пример: create database shop;
Drop database имя_БД;
Пример: Drop database shop;
Работастаблицами
Createtableимя_таблицы (имя_полятип_поля , …);
Create table proizvod (id int primary key, name varchar (20) not null, address varchar (30) not null, telvarchar (15) not null, country varchar (20) not null, license datetime);
Create table Tovar (id int primary key, name varchar (20) not null, kolsmallint not null, price int not null, srok_godvarchar(40) not null, kod_proizvint references proizvod (id));
Notnull – если указана эта конструкция, то элементы столбца всегда должны иметь определенное значение (не null)
Unique – значение каждого элемента столбца должно быть уникальным
Primarykey – столбец является первичным ключом
Параметры Unique и Primarykey являются взаимоисключаемыми.
Referencesимя_таблицы (имя_столбца) – данный столбец является внешним ключом, указывается имя таблицы и столбец на который он ссылается.
Удаление таблицы
Droptable<имя_таблицы>;
Пример: droptableTovar – удаление таблицы «товар»
Модификация таблицы
Добавление столбцов в таблицу:
Altertable<имя_таблицы>
ADD (<имя_столбца>тип_данных , …);
Alter table Tovar
Add (sostavvarchar (100) not null, opt_priceint not null);
Удаление столбцов из таблицы:
Altertable<имя_таблицы>
Drop (имя_строки1б имя_строки2, …);
Alter table Tovar
Drop (sostav, opt_price);
Изменение столбцов в таблице
Altertable<имя_таблицы>
Modify (имя_столбцатип_данных , …);
Modify (srok_goddatetime not null);
Основные функциональные возможности языка SQL приведены ниже.
Определение данных. Эта функция SQLпредставляет собой описание структуры поддерживаемых данных и организацию реляционных отношений (таблиц). Для ее реализации предназначены операторы создания базы данных, создания таблиц и доступа к данным.
Создание базы данных . Для создания новой базы данных используется оператор CREATE DATABASE. В структуре оператора указывается имя создаваемой базы данных.
Создание таблиц. Базовая таблица создается с помощью оператора CREATE TABLE. В этом операторе указываются имена полей, типы данных для них, длина (для некоторых типов данных). В SQL используются следующие типы данных:
INTEGER – целое число;
CHAR – символьное значение;
VARCHAR – символьное значение, сохраняются только непустые символы;
DECIMAL – десятичное число;
FLOAT – число с плавающей запятой;
DOUBLE PRECISION – удвоенная точность с плавающей точкой;
DATETIME – дата и время;
BOOL – булевое значение.
В операторе создания таблицы указываются ограничения на значения столбцов и на таблицу. Возможные ограничения показаны в табл. 4.8
Таблица 4.8 Ограничения на определяемые данные
Для реляционной модели данных существенным является указания внешнего ключа(FOREIGNKEY). При объявлении внешних ключей необходимо наложить соответствующие ограничения на столбец, например, NOT NULL.
В SQL-предложении CHECK обозначает семантические ограничения, обеспечивающие целостность данных, чтобы, например, ограничить множество допустимых значения определенного столбца.
Нельзя использовать оператор создания таблицы несколько раз для одной и той же таблицы. Если после ее создания обнаружились неточности в ее определении, то внести изменения можно с помощью оператора ALTER TABLE. Этот оператор предназначен для изменения структуры существующей таблицы: можно удалить или добавить поле к существующей таблице.
Манипулирование данными. SQL позволяет пользователю или прикладной программе изменять содержимое базы данных путем вставки новых данных, удаления или модификации существующих данных.
Вставка новых данных является процедурой добавления строк в базу данных и выполняется с помощью оператора INSERT.
Модификация данных предполагает изменения значений в одном или нескольких столбцах таблицы и выполняется с помощью оператора UPDATE. Пример:
SET сумма=сумма+1000.00
WHERE сумма>0
Удаление строк из таблицы осуществляется с помощью оператора DELETE. Синтаксис оператора имеет вид:
FROM таблица
Предложение WHERE не является обязательным, однако, если его не включить, то будут удалены все записи таблицы. Полезно использовать оператор SELECT c тем же синтаксисом, что и оператор DELETE, чтобы предварительно проверить, какие записи будут удалены.
Обеспечение целостности данных. Язык SQL позволяет определить достаточно сложные ограничения целостности, удовлетворение которым будет проверяться при всех модификациях базы данных. Контроль за результатами транзакций, обработка возникающих ошибок и координирование параллельной работы с базой данных нескольких приложений или пользователей обеспечивается операторами COMMIT(фиксирует удачное окончание текущей транзакции и начало новой) и ROLLBACK (необходимость отката – автоматического восстановления состояния базы данных на начало транзакции)
Выборка данных – одна из важнейших функций базы данных, которой соответствует оператор SELECT. Пример использования оператора был рассмотрен в предыдущем разделе.
В SQL можно создавать вложенные последовательности запросов (подзапросы). Существуют определенные типы запросов, которые лучше реализовывать с помощью подзапросов. К таким запросам относятся так называемые проверки существования. Предположим, что требуется получить данные о студентах, которые не имеют оценку «семь баллов». Если будет возвращено пустое множество, то это означает лишь одно – у каждого студента есть, по крайней мере, одна такая оценка.
Связывание таблиц . Операторы языка SQL позволяют извлекать данные более чем из одной таблицы. Одна из возможностей сделать это заключается в связывании таблиц по одному общему полю.
В операторе SELECT должно присутствовать ограничение на совпадение значений определенного столбца (поля). Тогда из связанных таблиц будут извлекаться только те строки, в которых значения заданного столбца совпадают. Название столбца указывается только вместе с названием таблицы; в противном случае оператор будет неоднозначным.
Можно использовать другие типы связывания таблиц: оператор INTER JOIN (внутреннее соединение) обеспечивает присутствие в результирующем наборе записей, совпадающие значения в связанных полях. Внешние соединения (OUTER JOIN) позволяют включить в результат запроса все строки из одной таблицы и соответствующие им строки из другой
Управление доступом. SQL обеспечивает синхронизацию обработки базы данных различными прикладными программами, защиту данных от несанкционированного доступа.
Доступ к данным в многопользовательской среде регулируется с помощью операторов GRANT и REVOKE. В каждом операторе необходимо указать пользователя, объект (таблицу, представление), по отношению к которому задаются полномочия, и сами полномочия. Например, оператор GRANT задает пользователю Х возможность производить выборку данных из таблицы ТОВАР:
GRANT SELECT ON ТОВАР TO X
Оператор REVOKE аннулирует все предоставленные ранее полномочия.
Встраивание SQL в прикладные программы . Реальные приложения обычно написаны на других языках, генерирующих код на языке SQL и передающих их в СУБД в виде текста в формате ASCII.
Стандартом фирмы IBM для SQL-продуктов регламентировано использование встроенного языка SQL. При написании прикладной программы ее текст представляет собой смесь команд основного языка программирования (например, C, Pascal, Cobol, Fortran, Assembler) и команд SQL со специальным префиксом, например. ExecSQL. Структура SQL-предложений расширена для размещения переменных основного языка в SQL-конструкции.
SQL-процессор видоизменяет вид программы в соответствии с требованиями компилятора основного языка программирования. Функция компилятора состоит в трансляции (перевод) программы с исходного языка программирования на язык, близкий к машинному. После компиляции прикладная программа (приложение) представляет собой самостоятельный модуль.
Диалекты языка SQL
В современных реляционных СУБД для описания и манипулирования данными используются диалекты языка SQL. Подмножество языка SQL, позволяющее создавать и описывать БД, называется DDL (Data Definition Language).
Первоначально язык SQL назывался SEQUEL(Structured English Query Language), потом SEQUEL/2, а затем просто – SQL. Сегодня язык SQL –фактический стандарт для реляционных СУБД.
Первый стандарт языка появился в 1989 г. – SQL-89 и поддерживался практически всеми коммерческими реляционными СУБД. Он имел общий характер и допускал широкое толкование. Достоинствами SQL-89 можно считать стандартизацию синтаксиса и семантики операторов выборки и манипулирования данными, а также фиксацию средств ограничения целостности базы данных. Однако в нем отсутствовал такой важный раздел как манипулирование схемой базы данных. Неполнота стандарта SQL-89 привела к появлению в 1992г. следующей версии языка SQL.
SQL2 (или SQL-92) охватывает практически все необходимые проблемы: манипулирование схемой базы данных, управление транзакциями и сессиями, поддерживает архитектуры клиент-сервер или средства разработки приложений.
Дальнейшим шагом развития языка является вариант SQL 3. Эта версия языка дополняется механизмом триггеров, определением произвольного типа данных, объектным расширением.
В настоящее время существует три уровня языка: начальный, промежуточный и полный. Многие производители своих СУБД применяют собственные реализации SQL, основанные как минимум на начальном уровне соответствующего стандарта ANSI, и содержащие некоторые расширения, специфические для той или иной СУБД. В табл. 4.9 приведены примеры диалектов SQL.
Таблица 4.9 Диалекты языка SQL
| СУБД | Язык запросов |
| СУБД System R | SQL |
| DB2 | SQL |
| Access | SQL |
| SYBASE SQL Anywhere | Watcom-SQL |
| SYBASE SQL Server | Transact_SQL |
| My SQL | SQL |
| Oracle | PL/SQL |
В объектно-ориентированных БД используется язык объектных запросов OQL (Object Query Language). За основу языка OQL была взята команда SELECT языка SQL2 и добавлены возможность направлять запрос к объекту или коллекции объектов, а также возможность вызывать методы в рамках одного запроса.
Совместимость многих используемых диалектов SQL обусловливает совместимость СУБД. Так, СУБД SYBASE SQL Anywhere максимально, насколько это возможно для СУБД такого класса, совместима с СУБД SYBASE SQL Server. Одной из сторон такой совместимости является поддержка в SYBASE SQL Anywhere такого диалекта языка SQL как Transact-SQL . Этот диалект используется в SYBASE SQL Server и может применяться в SYBASE SQL Anywhere наряду с собственным диалектом языка SQL - Watcom-SQL .
Контрольные вопросы
1. Как можно классифицировать СУБД?
2. Какие модели баз данных существуют?
3. Что является основными элементами инфологических моделей?
4. Какие типы связей между сущностями существуют?
5. Что такое ER-диаграммы и для чего они используются?
6. Что позволяет делать процедура нормализации таблиц?
7. Назовите языковые и программные средства СУБД?
8. К каому типу относится СУБД MS Access?
9. Назовите основные объекты СУБД MS Access?
10. Для чего используются основные операторы языка SQL?
05.01.15 28.1KПорой так хочется привести свои мысли в порядок, разложить их по полочкам. А еще лучше в алфавитной и тематической последовательности, чтобы, наконец, наступила ясность мышления. Теперь представьте, какой бы хаос творился в «электронных мозгах » любого компьютера без четкой структуризации всех данных и Microsoft SQL Server :
Данный программный продукт представляет собой систему управления базами данных (СУБД ) реляционного типа, разработанную корпорацией Microsoft . Для манипуляции данными используется специально разработанный язык Transact-SQL . Команды языка для выборки и модификации базы данных построены на основе структурированных запросов:

То есть их инструментарий легко взаимодействует между собой, что во многом упрощает процесс разработки и написания программного кода. Примером такой взаимосвязи является среда программирования MS Visual Studio . В ее инсталляционный пакет уже входит SQL Server Express Edition .
Конечно, это не единственная популярная СУБД на мировом рынке. Но именно она является более приемлемой для компьютеров, работающих под управлением Windows, за счет своей направленности именно на эту операционную систему. И не только из-за этого.
Преимущества MS SQL Server :
Клиентская часть системы поддерживает создание пользовательских запросов и их отправку для обработки на сервер.
Особенности этой популярной СУБД легче всего прослеживаются при рассмотрении истории эволюции всех ее версий. Более подробно мы остановимся лишь на тех выпусках, в которые разработчики вносили весомые и кардинальные изменения:
В базовый комплект системы входит несколько утилит для настройки SQL Server . К ним относятся:
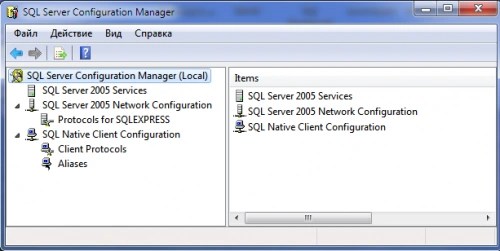


Набор утилит, входящих в Microsoft SQL Server , может отличаться в зависимости от версии и редакции программного пакета. Например, в версии 2008 года вы не найдете SQL Server Surface Area Configuration .
Для примера будет использована версия сервера баз данных выпуска 2005 года. Запуск сервера можно произвести несколькими способами:

Для запуска сервера баз данных запускаем приложение. В диалоговом окне «Соединение с сервером » в поле «Имя сервера » выбираем нужный нам экземпляр. В поле «Проверка подлинности » оставляем значение «Проверка подлинности Windows ». И нажимаем на кнопку «Соединить »:

Перед тем, как запустить MS SQL Server , нужно кратко ознакомиться с основными возможностями его настройки и администрирования. Начнем с более детального обзора нескольких утилит из состава СУБД :
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
План
Введение………………………………………………...…………………………3
Глава I. Теоретические сведения о языке запросов SQL……………...………..4
1.1. Понятие о реляционной базе данных…………………………..…………4
1.2. Понятие о SQL-языке…………………………………………...………...10
1.3. Интерактивный и вложенный SQL……………………………...……….12
1.4. Субподразделения SQL……………………………………………...……13
1.5. Типы данных………………………………………………………...…….13
1.6. SQL-несогласованности……………………………………………...…...16
Глава II. Использование языка SQL для извлечения информации………...…18
2.1. Создание запроса………………………………………………………...….18
2.2. Команда SELECT……………………………………………………...…….19
2.3. Команда DISTINCT..……………………………………………………......22
2.4. Предложения команд……………………………………………………….24
Заключение…………………………………………………………………...…..27
Список использованной литературы……………………………………..…….28
Введение
Большинство современных СУБД построено на реляционной модели данных. Для получения информации из отношений (таблиц) базы данных в качестве языка манипулирования данными в теоретическом плане используются три абстрактных языка: язык реляционной алгебры; язык реляционного исчисления на кортежах; язык реляционного исчисления на доменах.
В качестве практического языка работы с данными в середине 70-х годов фирмой IBM разработан язык структурных запросов SQL, ставший впоследствии стандартом de-facto при работе с базами данных. Наметившееся в настоящее время переход к крупным корпоративным СУБД типа Oracle, Informix, Sybase, DB2, Progress делает актуальным изучение языка SQL как в практическом плане, так и чисто теоретически, поскольку в основе элементов языка SQL лежат положения теории отношений, теории множеств и логики.
Цель курсовой работы - анализ возможностей языка SQL.
Для достижения поставленной цели необходимо решить следующие задачи:
· Изучить литературу по теме;
· Рассмотреть структуру SQL;
· Определить спецификацию и стандарты языка;
· Изучить применение SQL для извлечения информации.
Глава I . Теоретические сведения о языке запросов SQL
1.1. Понятие о реляционной базе данных
SQL (обычно произносится как "Sequel") символизирует собой Структурированный Язык Запросов. Это - язык, который дает возможность работать в реляционных базах данных, которые являются наборами связанной информации сохраняемой в таблицах.
Мир баз данных становится все более и более единым, что привело к необходимости создания стандартного языка, который мог бы использоваться, чтобы функционировать в большом количестве различных видов компьютерных сред. Стандартный язык позволит пользователям знающим один набор команд, использовать их, чтобы создавать, отыскивать, изменять, и передавать информацию независимо от того работают ли они на персональном компьютере, сетевой рабочей станции, или на универсальной ЭВМ.
В нашем все более и более взаимосвязанном компьютерном мире, пользователь, снабженный таким языком, имеет огромное преимущество в использовании и обобщении информации из ряда источников с помощью большого количества способов.
Элегантность и независимость от специфики компьютерных технологий, а также его поддержка лидерами промышленности в области технологии реляционных баз данных, сделало SQL, и вероятно в течение обозримого будущего оставит его, основным стандартным языком. По этой причине, любой, кто хочет работать с базами данных 90-х годов должен знать SQL.
Стандарт SQL определяется ANSI (Американским Национальным Институтом Стандартов) и в данное время также принимается ISO (Международной организацией по стандартизации). Однако, большинство коммерческих программ баз данных расширяют SQL без уведомления ANSI, добавляя разные другие особенности в этот язык, которые, как они считают, будут весьма полезны. Иногда они несколько нарушают стандарт языка, хотя хорошие идеи имеют тенденцию развиваться и вскоре становиться стандартами "рынка" сами по себе в силу полезности своих качеств.
Реляционная база данных - это тело связанной информации, сохраняемой в двумерных таблицах. Напоминает адресную или телефонную книгу. В книге имеется большое количество входов, каждый из которых соответствует определенной особенности. Для каждой такой особенности, может быть несколько независимых фрагментов данных, например имя, телефонный номер, и адрес. Предположим, что вы должны сформатировать эту адресную книгу в виде таблицы со строками и столбцами. Каждая строка (называемая также записью) будет соответствовать определенной особенности; каждый столбец будет содержать значение для каждого типа данных - имени, телефонного номера, и адреса представляемого в каждой строке. Адресная книга могла бы выглядеть следующим образом:
Полученное является основой реляционной базы данных - а именно, двумерной (строка и столбец) таблицей информации. Однако, реляционные базы данных редко состоят из одной таблицы. Такая таблица меньше чем файловая система. Создав несколько таблиц взаимосвязанной информации, можно выполнить более сложные и мощные операции с данными. Мощность базы данных зависит от связи, которую можно создать между фрагментами информации, а не от самого фрагмента информации.
На примере адресной книги можно начать обсуждение базы данных которая может реально использоваться в деловой ситуации. Предположим, что персонажи в первой таблице (адресной книги) - это пациенты больницы. В другой таблице, мы могли бы запомнить дополнительную информацию об этих пациентах. Столбцы второй таблицы могли бы быть помечены как Пациент, Доктор, Страховка, и Баланс.
Много мощных функций можно выполнить извлекая информацию из этих таблиц согласно указанным параметрам, особенно когда эти параметры включают в себя фрагменты информации связанные в различных таблицах друг с другом. Например, возьмем - докторов. Предположим доктор Halben захотел получить номера телефонов всех своих пациентов. Чтобы извлечь эту информацию, он мог бы связать таблицу с номерами телефонов пациентов (по адресной книге) с таблицей, которая бы указывала, какой из пациентов - его. Хотя, в этом простом примере, он мог бы держать это в голове и сразу получать номера телефонов пациентов Grillet и Brock, эти таблицы могут быть слишком большими и слишком сложными. Программы реляционной базы данных разрабатывались для того чтобы обрабатывать большие и сложные совокупности данных такого типа, что очевидно является более универсальным методом в деловом мире. Даже если бы база данных больницы содержала сотни или тысячи имен - как это вероятно и бывает на практике - одна команда SQL могла бы выдать доктору Halben информацию в которой он нуждался почти немедленно.
Чтобы поддерживать максимальную гибкость, строки таблицы, по определению, не должны находиться ни в каком определенном порядке. С этой точки зрения, в этом структура базы данных отличается от нашей адресной книги. Вход в адресную книгу обычно упорядочивается в алфавитном порядке. В системах с реляционной базой данных, имеется одна мощная возможность для пользователей - это способность упорядочивать информацию так чтобы они могли восстанавливать ее.
Рассмотрим вторую таблицу. Иногда необходимо видеть эту информацию упорядоченной в алфавитном порядке по именам, иногда в возрастающем или убывающем порядке, а иногда сгруппированной по отношению к какому-нибудь доктору. Наложение порядка набора в строках будет сталкиваться со способностью заказчика изменять его, поэтому строки всегда рассматриваются как неупорядоченные. По этой причине, вы не можете просто сказать: " Мы хотим посмотреть пятую строку таблицы. " Пренебрегая порядком, в котором данные вводились или любым другим критерием, мы определим, не ту строку, хотя она и будет пятой. Строки таблицы, которые рассматриваются, не будут в какой-либо определенной последовательности.
По этим и другим причинам, вы должны иметь столбец в вашей таблице который бы уникально идентифицировал каждую строку. Обычно, этот столбец содержит номер - например, номер пациента назначаемый каждому пациенту. Конечно, вы могли бы использовать имя пациентов, но возможно, что имеется несколько Mary Smiths; и в этом случае, вы не будете иметь другого способа, чтобы отличить этих пациентов друг от друга.
Вот почему номера так необходимы. Такой уникальный столбец (или уникальная группа столбцов), используемый чтобы идентифицировать каждую строку и хранить все строки отдельно, называются - первичными ключами таблицы.
Первичные ключи таблицы важный элемент в структуре базы данных. Они - основа вашей системы записи в файл; и когда вы хотите найти определенную строку в таблице, вы ссылаетесь к этому первичному ключу. Кроме того, первичные ключи гарантируют, что ваши данные имеют определенную целостность. Если первичный ключ правильно используется и поддерживается, вы будете знать что нет пустых строк таблицы и что каждая строка отличается от любой другой строки.
В отличие от строк, столбцы таблицы (также называемые полями) упорядочиваются и именуются. Таким образом, в нашей таблице адресной книги, возможно указать на " адрес столбца " или на " столбец 3 ". Конечно, это означает, что каждый столбец данной таблицы должен иметь уникальное имя чтобы избежать неоднозначности. Лучше всего если эти имена указывают на содержание поля.
Таблицы 1.1, 1.2, и 1.3 составляют реляционную базу данных, которая является минимально достаточной, чтобы легко ее отслеживать, и достаточно полной, чтобы иллюстрировать главные понятия и практику использования SQL.
Первый столбец каждой таблицы содержит номера, чьи значения различны для каждой строки. Это - первичные ключи таблиц. Некоторые из этих номеров также показаны в столбцах других таблиц. В этом нет ничего неверного. Они показывают связь между строками, которые используют значение принимаемое из первичного ключа, и строками где это значение используется в самом первичном ключе.
Таблица 1.1 - Продавцы
Таблица 1.2 - Заказчики
Таблица 1.3 - Порядки
Например, поле snum в таблице Заказчиков указывает, какому продавцу назначен данный заказчик. Номер поля snum связан с таблицей Продавцов, которая дает информацию об этих продавцах. Очевидно, что продавец которому назначены заказчики должен уже существовать - то есть, значение snum из таблицы Заказчиков должно также быть представлено в таблице Продавцов. Если это так, то говорят, что " система находится в состоя нии справочной целостности "
Рассмотрим эти три таблицы и значения их полей.
Здесь показаны столбцы Таблицы 1.1
Таблица 1.2 содержит следующие столбцы:
И имеются столбцы в Таблице 1.3:
1.2. Понятие о SQL -языке
SQL это язык, ориентированный специально на реляционные базы данных. Он устраняет много работы, которую вы должны были бы сделать, если бы вы использовали универсальный язык программирования, например C. Чтобы сформировать реляционную базу данных на C, вам необходимо было бы начать с самого начала. Вы должны были бы определить объект - называемый таблицей, которая могла бы расти, чтобы иметь любое число строк, а затем создавать постепенно процедуры для помещения значений в нее и извлечения из них. Если бы вы захотели найти некоторые определенные строки, вам необходимо было бы выполнить по шагам процедуру, подобную следующей:
Рассмотрите строку таблицы.
Выполните проверку - является ли эта строка одной из строк которая вам нужна.
Если это так, сохраните ее где-нибудь пока вся таблица не будет проверена.
Проверьте имеются ли другие строки в таблице.
Если имеются, возвратитесь на шаг 1.
Если строк больше нет, вывести все значения сохраненные в шаге 3.
(Конечно, это не фактический набор C команд, а только логика шагов которые должны были бы быть включены в реальную программу). SQL сэкономит все это. Команды в SQL могут работать со всеми группами таблиц как с единым объектом и могут обрабатывать любое количество информации извлеченной или полученной из их, в виде единого модуля.
Стандарт SQL определяется с помощью кода ANSI (Американский Национальный Институт Стандартов). SQL не изобретался ANSI. Это по существу изобретение IBM. После того как появился ряд конкурирующих программ SQL на рынке, ANSI определил стандарт к которому они должны быть приведены (определение таких стандартов и является функцией ANSI).
Однако после этого, появились некоторые проблемы. Возникли они в результате стандартизации ANSI в виде некоторых ограничений. Так как не всегда ANSI определяет то что является наиболее полезным, то программы пытаются соответствовать стандарту ANSI не позволяя ему ограничивать их слишком сильно. Это, в свою очередь, ведет к случайным несогласованностям. Программы Баз Данных обычно дают ANSI SQL дополнительные особенности и часто ослабляют многие ограничения из большинства из них.
SQL имеет определенные специальные термины, которые используются чтобы описывать его. Среди них - такие слова как запрос, предложение, и предикат, которые являются важнейшими в описании и понимании языка но не означают что-нибудь самостоятельное для SQL.
Команды, или предложения, являются инструкциями, которыми мы обращаемся к SQL базе данных. Команды состоят из одной или более отдельных логических частей называемых предложениями. Предложения начинаются ключевым словом для которого они являются проименованными, и состоят из ключевых слов и аргументов. Например предложения с которыми мы можем сталкиваться - это " FROM Salespeople " и " WHERE city = "London".
Аргументы завершают или изменяют значение предложения. В примерах выше, Salespeople - аргумент, а FROM - ключевое слово предложения FROM.
Аналогично, " city = "London" " - агрумент предложения WHERE. Объекты - структуры в базе данных которым даны имена и сохраняются в памяти.
Они включают в себя базовые таблицы, представления (два типа таблиц), и индексы.
1.3. Интерактивный и вложенный SQL
Имеются два SQL: Интерактивный и Вложенный. Большей частью, обе формы работают одинаково, но используются различно. Интерактивный SQL используется для функционирования непосредственно в базе данных чтобы производить вывод для использования его заказчиком. В этой форме SQL, когда вы введете команду, она сейчас же выполнится и вы сможете увидеть вывод (если он вообще получится) - немедленно.
Вложенный SQL состоит из команд SQL помещенных внутри программ, которые обычно написаны на некотором другом языке (типа КОБОЛА или Паскаля).
Это делает эти программы более мощными и эффективным. Однако, допуская эти языки, приходится иметь дело с структурой SQL и стилем управления данных который требует некоторых расширений к интерактивному SQL. Передача SQL команд во вложенный SQL является выдаваемой ("passed off") для переменных или параметров используемых программой в которую они были вложены.
1.4. Субподразделения SQL
И в интерактивной, и во вложенной формах SQL, имеются многочисленные части, или субподразделения.
К сожалению, эти термины не используются повсеместно во всех реализациях. Они подчеркиваются ANSI и полезны на концептуальном уровне, но большинство SQL программ практически не обрабатывают их отдельно, так что они по существу становятся функциональными категориями команд SQL.
DDL (Язык Определения Данных) - так называемый Язык Описания Схемы в ANSI, состоит из команд, которые создают объекты (таблицы, индексы, просмотры, и так далее) в базе данных.
DML (Язык Манипулирования Данными) - это набор команд которые определяют какие значения представлены в таблицах в любой момент времени.
DCD (Язык Управления Данными) состоит из средств которые определяют, разрешить ли пользователю выполнять определенные действия или нет. Они являются составными частями DDL в ANSI. Это не различные языки, а разделы команд SQL сгруппированных по их функциям.
1.5. Типы данных
Не все типы значений, которые могут занимать поля таблицы - логически одинаковые. Наиболее очевидное различие - между числами и текстом. Вы не можете помещать числа в алфавитном порядке или вычитать одно имя из другого. Так как системы с реляционной базой данных базируются на связях между фрагментами информации, различные типы данных должны понятно отличаться друга от друга, так чтобы соответствующие процессы и сравнения могли быть в них выполнены.
В SQL, это делается с помощью назначения каждому полю - типа данных который указывает на тип значения, которое это поле может содержать.
Все значения в данном поле должны иметь одинаковый тип. В таблице Заказчиков, например, cname и city - содержат строки текста для оценки, snum, и cnum - это уже номера. По этой причине, вы не можете ввести значение Highest (Наивысший) или значение None (Никакой) в поле rating, которое имеет числовой тип данных. Это ограничение удачно, так как оно налагает некоторую структурность на ваши данные. Вы часто будете сравнивать некоторые или все значения в данном поле, поэтому вы можете выполнять действие только на определенных строках, а не на всех. Вы не могли бы сделать этого, если бы значения полей имели смешанный тип данных.
К сожалению, определение этих типов данных является основной областью, в которой большинство коммерческих программ баз данных и официальный стандарт SQL, не всегда совпадают. ANSI SQL стандарт распознает только текст и тип номера, в то время как большинство коммерческих программ используют другие специальные типы. Такие как, DATA (ДАТА) и TIME (ВРЕМЯ) - фактически почти стандартные типы (хотя точный формат их меняется). Некоторые пакеты также поддерживают такие типы, как например MONEY (ДЕНЬГИ) и BINARY (ДВОИЧНЫЕ). (MONEY - это специальная система исчисления используемая компьютерами. Вся информация в компьютере передается двоичными числами и затем преобразовываются в другие системы, что бы мы могли легко использовать их и понимать).
ANSI определяет несколько различных типов значений чисел, различия между которыми - довольно тонки и иногда их путают.
Сложность числовых типов ANSI можно, по крайней мере частично, объяснить усилием сделать вложенный SQL, совместимым с рядом других языков.
Два типа чисел ANSI, INTEGER (ЦЕЛОЕ ЧИСЛО) и DECIMAL (ДЕСЯТИЧНОЕ ЧИСЛО) (которые можно сокращать как INT и DEC, соответственно), будут адекватны для наших целей, также как и для целей большинства практических деловых прикладных программ. Естественно, что тип ЦЕЛОЕ можно представить как ДЕСЯТИЧНОЕ ЧИСЛО, которое не содержит никаких цифр справа от десятичной точки.
Тип для текста - CHAR (или СИМВОЛ), который относится к строке текста. Поле типа CHAR имеет определенную длину, которая определяется максимальным числом символов, которые могут быть введены в это поле.
Больше всего реализаций также имеют нестандартный тип называемый VARCHAR (ПЕРЕМЕННОЕ ЧИСЛО СИМВОЛОВ), который является текстовой строкой которая может иметь любую длину до определенного реализацией максимума (обычно 254 символа). CHARACTER и VARCHAR значения включаются в одиночные кавычки как "текст". Различие между CHAR и VARCHAR в том, что CHAR должен резервировать достаточное количество памяти для максимальной длины строки, а VARCHAR распределяет память так как это необходимо.
Символьные типы состоят из всех печатных символов, включая числа.
Однако, номер 1 не то же что символ "1". Символ "1" - только другой печатный фрагмент текста, не определяемый системой как наличие числового значения 1.
Например 1 + 1 = 2, но "1" + "1" не равняется "2".
Символьные значения сохраняются в компьютере как двоичные значения, но показываются пользователю как печатный текст. Преобразование следует за форматом определяемым системой, которую вы используете. Этот формат преобразования будет одним из двух стандартных типов (возможно с расширениями) используемых в компьютерных системах: в ASCII коде (используемом во всех персональных и малых компьютерах) и EBCDIC коде (Расширенном Двоично-Десятичном Коде Обмена Информации) (используемом в больших компьютерах). Определенные операции, такие как упорядочивание в алфавитном порядке значений поля, будет изменяться вместе с форматом.
1.6. SQL несогласованности
Имеются самостоятельные несогласованности внутри продуктов мира SQL. SQL появился из коммерческого мира баз данных как инструмент, и был позже превращен в стандарт ANSI. К сожалению, ANSI не всегда определяет наибольшую пользу, поэтому программы пытаются соответствовать стандарту ANSI не позволяя ему ограничивать их слишком сильно. ANSI - вид минимального стандарта - вы можете делать больше чем он это позволяет, но вы должны быть способны получить те же самые результаты что и при выполнении той же самой задачи.
SQL обычно находится в компьютерных системах которые имеют больше чем одного пользователя, и следовательно должны делать различие между ними. Обычно, в такой системе, каждый пользователь имеет некий вид кода проверки прав который идентифицирует его или ее (терминология изменяется). В начале сеанса с компьютером, пользователь входит в систему (регистрируется), сообщая компьютеру, кто этот пользователь, идентифицированный с помощью определенного ID(Идентификатора). Любое количество людей использующих тот же самый ID доступа, являются отдельными пользователями; и аналогично, один человек может представлять большое количество пользователей (в разное время), используя различные доступные Идентификаторы.
SQL следует этому примеру. Действия в большинстве сред SQL приведены к специальному доступному Идентификатору который точно соответствует определенному пользователю. Таблица или другой объект принадлежит пользователю, который имеет над ним полную власть. Пользователь может или не может иметь привилегии чтобы выполнять действие над объектом.
Специальное значение - USER (ПОЛЬЗОВАТЕЛЬ) может использоваться как аргумент в команде. Оно указывает на доступный Идентификатор пользователя, выдавшего команду.
Выводы по главе I :
В первой главе было дано понятие реляционной базы данных. Также были изучены некоторые фундаментальные принципы относительно того, как сделаны таблицы - как работают строки и столбцы, как первичные ключи отличают строки друга друга, и как столбцы могут ссылаться к значениям в других столбцах. Мы определили, что запись это синоним строки, и что поле это синоним столбца. Мы ознакомились с таблицами примеров. Краткие и простые, они способны показать большинство особенностей языка.
Также было дано понятие SQL-языку, его некоторые условные обозначения и термины, рассмотрена его структура, использование SQL-языка, предоставление данных и их определение (и некоторые несогласованности появляющиеся при этом).
Глава II . Использование языка SQL для извлечения информации из таблиц
2.1. Создание запроса
SQL символизирует собой Структурированный Язык Запросов. Запросы - вероятно наиболее часто используемый аспект SQL. Фактически, для категории SQL пользователей, маловероятно чтобы кто-либо использовал этот язык для чего-то другого. По этой причине, мы будем начинать наше обсуждение SQL с обсуждения запроса и как он выполняется на этом языке.
Запрос - команда которая дается вашей программе базы данных, и которая сообщает ей чтобы она вывела определенную информацию из таблиц в память. Эта информация обычно посылается непосредственно на экран компьютера или терминала, хотя, в большинстве случаев, ее можно также послать принтеру, сохранить в файле (как объект в памяти компьютера), или представить как вводную информацию для другой команды или процесса.
Запросы обычно рассматриваются как часть языка DML. Однако, так как запрос не меняет информацию в таблицах, а просто показывает ее пользователю, мы будем рассматривать запросы как самостоятельную категорию среди команд DML которые производят действие, а не просто показывают содержание базы данных.
Все запросы в SQL состоят из одиночной команды. Структура этой команды обманчиво проста, потому что вы должны расширять ее так чтобы выполнить высоко сложные оценки и обработки данных. Эта команда называется - SELECT (ВЫБОР).
2.2. К оманда SELECT
В самой простой форме, команда SELECT просто инструктирует базу данных чтобы извлечь информацию из таблицы. Например, можно вывести таблицу Продавцов, напечатав следующее:
SELECT snum, sname, sity, comm
FROM Salespeople;
Вывод для этого запроса показывается в таблице 2.1.
Таблица 2.1 - Команда SELECT
|
SQL Execution Log |
||||
|
SELECT snum, sname, sity, comm FROM Salespeople; |
||||
Другими словами, эта команда просто выводит все данные из таблицы. Большинство программ будут также давать заголовки столбца как выше, а некоторые позволяют детальное форматирование вывода, но это уже вне стандартной спецификации.
Имеется объяснение каждой части этой команды:
SELECT - ключевое слово, которое сообщает базе данных что эта команда - запрос. Все запросы начинаются этим словом, сопровождаемым пробелом.
Snum, sname - это - список столбцов из таблицы которые выбираются запросом. Любые столбцы не перечисленные здесь не будут включены в вывод команды. Это, конечно, не значит что они будут удалены или их информация будет стерта из таблиц, потому что запрос не воздействует на информацию в таблицах; он только показывает данные.
FROM FROM - ключевое слово, подобно SELECT, которое должно Salespeople быть представлено в каждом запросе. Оно сопровождается пробелом и затем именем таблицы используемой в качестве источника информации. В данном случае - это таблица Продавцов (Salespeople).
Точка с запятой используется во всех интерактивных командах SQL чтобы сообщать базе данных что команда заполнена и готова выполниться.
В некоторых системах наклонная черта влево (\) в строке, является индикатором конца команды.
Естественно, запрос такого характера не обязательно будет упорядочивать вывод любым указанным способом. Та же самая команда выполненная с теми же самыми данными но в разное время не сможет вывести тот же самый порядок. Обычно, строки обнаруживаются в том порядке в котором они найдены в таблице, поскольку как мы установили в предыдущей главе - этот порядок произволен. Это не обязательно будет тот порядок в котором данные вводились или сохранялись. Вы можете упорядочивать вывод командами SQL непосредственно: с помощью специального предложения.
Использование возврата (Клавиша ENTER) является произвольным. Нужно точно установить, как удобнее составить запрос, в несколько строк или в одну строку, следующим образом:
SELECT snum, sname, city, comm FROM Salespeople;
С тех пор как SQL использует точку с запятой чтобы указывать конец команды, большинство программ SQL обрабатывают возврат (через нажим Возврат или клавишу ENTER) как пробел. Это - хорошая идея, чтобы использовать возвраты и выравнивание, чтобы сделать ваши команды более легкими для чтения и более правильными.
Звездочка (*) может применяться для вывода полного списка столбцов следующим образом:
FROM Salespeople;
Это приведет к тому же результату что и предыдущая команда.
В общем случае, команда SELECT начинается с ключевого слова SELECT, сопровождаемого пробелом. После этого должен следовать список имен столбцов которые вы хотите видеть, отделяемые запятыми. Чтобы увидеть все столбцы таблицы, можно заменить этот список звездочкой (*). Ключевое слово FROM следующее далее, сопровождается пробелом и именем таблицы запрос к которой делается. В заключение, точка с запятой (;) должна использоваться чтобы закончить запрос и указать что команда готова к выполнению.
Команда SELECT способна извлечь строго определенную информацию из таблицы. Сначала можно увидеть только определенные столбцы таблицы. Это выполняется легко, простым исключением столбцов, которые не нужны, из части команды SELECT. Например, запрос
SELECT sname, comm
FROM Salespeople;
будет производить вывод показанный в Таблице 2.2:
Таблица 2.2 - Выбор определенных столбцов
|
SQL Execution Log |
||
|
SELECT snum, comm FROM Salespeople; |
||
Могут иметься таблицы, которые имеют большое количество столбцов содержащих данные, не все из которых являются относящимися к поставленной задаче. Следовательно, можно найти способ подбора и выбора только полезных столбцов.
Даже если столбцы таблицы, по определению, упорядочены, это не означает что они будут восстанавливаться в том же порядке. Конечно, звездочка (*) покажет все столбцы в их естественном порядке, но если они будут указаны отдельно, мы можем получить их в нужном порядке. Рассмотрим таблицу Порядков, содержащую дату приобретения (odate), номер продавца (snum), номер порядка (onum), и суммы приобретения (amt):
SELECT odate, snum, onum, amt
Вывод этого запроса показан в Таблице 2.3.
Таблица 2.3 - Реконструкция столбцов
|
SQL Execution Log |
||||
|
SELECT odate, snum, onum, amt FROM Orders; |
||||
Структура информации в таблицах - это просто основа для активной перестройки структуры в SQL.
2.3. Команда DISTINCT
Команда DISTINCT (ОТЛИЧИЕ) - аргумент, который способен устранять двойные значения из предложения SELECT. Предположим, что нам нужно, знать какие продавцы в настоящее время имеют свои порядки в таблице Порядков. Под порядком понимается запись в таблицу Порядков, регистрирующую приобретения сделанные в определенный день определенным заказчиком у определенного продавца на определенную сумму. Нам не нужно знать, сколько порядков имеет каждый; нам нужен только список номеров продавцов (snum). Поэтому можно ввести:
для получения вывода показанного в Таблице 2.4.
Таблица 2.4 - SELECT с дублированием номеров продавцов
|
SQL Execution Log |
|
|
SELECT snum FROM Orders; |
|
Для получения списка без дубликатов, для удобочитаемости, можно ввести следующее:
SELECT DISTINCT snum
Вывод для этого запроса показан в Таблице 2.5.
Другими словами, DISTINCT следит за тем, какие значения были ранее, так что бы они не были продублированы в списке. Это - полезный способ избежать избыточности данных. Чтобы не потерять некоторые данные, не нужно безоглядно использовать DISTINCT, потому что это может скрыть какую-то проблему или какие-то важные данные.
DISTINCT может указываться только один раз в данном предложении SELECT. Если предложение выбирает многочисленные поля,
Таблица 2.5 - SELECT без дублирования
|
SQL Execution Log |
|
|
SELECT DISTINCT snum FROM Orders; |
|
DISTINCT опускает строки где все выбранные поля идентичны. Строки в которых некоторые значения одинаковы а некоторые различны - будут сохранены. DISTINCT, фактически, приводит к показу всей строки вывода, не указывая полей (за исключением когда он используется внутри агрегатных функций), так что нет никакого смысла чтобы его повторять.
Вместо DISTINCT, можно указать - ALL. Это будет иметь противоположный эффект, дублирование строк вывода сохранится. Так как это - тот же самый случай, когда не указывается ни DISTINCT ни ALL, то ALL - по существу скорее пояснительный, а не действующий аргумент.
2.4. Предложения команд
Таблицы имеют тенденцию становиться очень большими, поскольку с течением времени, все большее и большее количество строк в нее добавляется. Поскольку обычно из них только определенные строки представляют интерес, SQL дает возможность устанавливать критерии, чтобы определить, какие строки будут выбраны для вывода.
WHERE - предложение команды SELECT, которое позволяет устанавливать предикаты, условие которых может быть или верным или неверным для любой строки таблицы. Команда извлекает только те строки из таблицы для которой такое утверждение верно. Например, нам нужно видеть имена и комиссионные всех продавцов в Лондоне. Можно ввести такую команду:
SELECT sname, city
FROM Salespeople;
WHERE city = "LONDON";
Когда предложение WHERE представлено, программа базы данных просматривает всю таблицу по одной строке и исследует каждую строку чтобы определить верно ли утверждение. Следовательно, для записи Peel, программа рассмотрит текущее значение столбца city, определит что оно равно "London", и включит эту строку в вывод. Запись для Serres не будет включена, и так далее.
Вывод для вышеупомянутого запроса показан в Таблице 2.6.
Таблица 2.6 - SELECT c предложением WHERE
|
SQL Execution Log |
|
|
SELECT sname, city FROM Salespeople WHERE city = "London" |
|
Попробуем пример с числовым полем в предложении WHERE. Поле rating таблицы Заказчиков предназначено чтобы разделять заказчиков на группы основанные на некоторых критериях которые могут быть получены в итоге через этот номер. Возможно это - форма оценки кредита или оценки основанной на томе предыдущих приобретений. Такие числовые коды могут быть полезны в реляционных базах данных как способ подведения итогов сложной информации. Можно выбрать всех заказчиков с рейтингом 100, следующим образом:
WHERE rating = 100;
Одиночные кавычки не используются здесь потому, что оценка - это числовое поле. Результаты запроса показаны в Таблице 2.7.
Можно использовать номера столбцов, устранять дубликаты, или переупорядочивать столбцы в команде SELECT которая использует WHERE. Однако можно изменять порядок столбцов для имен только в предложении SELECT, но не в предложении WHERE.
Таблица 2.7 - SELECT с числовым полем в предикате
|
SQL Execution Log |
|||||
|
SELECT * FROM Customers WHERE rating = 100; |
|||||
В ыводы по главе II :
Теперь мы знаем несколько способов заставить таблицу давать необходимую информацию, а не просто выбрасывать наружу все ее содержание. Есть возможность переупорядочивать столбцы таблицы или устранять любую из них, а также решать, видеть дублированные значения или нет.
Наиболее важно то, что можно устанавливать условие называемое предикатом, которое определяет или не определяет указанную строку таблицы из тысяч таких же строк, будет ли она выбрана для вывода.
Заключение
Завершая работу можно прийти к выводу, что SQL - это высокоуровневый язык программирования, предназначенный для работы с базами данных. Позволяет модифицировать данные, составлять и выполнять запросы, выводить результаты в виде отчетов. В настоящее время является общепринятым стандартом для систем управления базами данных реляционного типа.
Язык SQL обычно используется вместе с универсальными языками программирования Си, Паскаль и др., или языками управления базами данных Fox, dBASE IV и др.
Список использованной литературы
1. Ф. Андон, В. Резниченко Язык запросов SQL: Учебный курс. - СПб: Питер, 2006.
2. К. Дейт Руководство по реляционной СУБД DB2. - М.: Финансы и статистика, 1988. - 320 с.
3. В.В. Кириллов Основы проектирования реляционных баз данных. Учебное пособие. - СПб.: ИТМО, 1994. - 90 с.
4. М. Мейер Теория реляционных баз данных. - М.: Мир, 1987. - 608 с.
5. Распределенные СУБД. Informix. Ч.1. Основы работы с базами данных. - Методические указания для выполнения лабораторных работ / В.М. Стасышин - Новосибирск: НГТУ, 1995.
6. Дж. Ульман Базы данных на Паскале. - М.: Машиностроение, 1990. - 386 с.
Общие данные об основных операторах языка SQL. Интерактивный режим работы. Использование языка SQL для выбора информации из таблиц, для вставки, редактирования и удаления данных в них. Связь между операциями реляционной алгебры и операторами языка SQL.
реферат , добавлен 06.02.2015
Понятие и общая характеристика языка программирования РНР, принципы и этапы его работы, синтаксис и ассоциируемые массивы. Обработка исключений в языке Java. Работа с базами данных с помощью JDBC. Изучение порядка разработки графического интерфейса.
презентация , добавлен 13.06.2014
Понятие реляционной модели данных, целостность ее сущности и ссылок. Основные этапы создания базы данных, связывание таблиц на схеме данных. Проектирование базы данных книжного каталога "Books" с помощью СУБД Microsoft Access и языка запросов SQL.
курсовая работа , добавлен 25.11.2010
Общие сведения об истории создания и стандартах SQL: международный стандарт 1989 г., 1992 г. (SQL2), стандарт SQL: 1999 (SQL3). Интерактивный и вложенный SQL. Cубподразделения SQL. Структурированный язык запросов для создания и изменения таблиц.
реферат , добавлен 14.10.2011
Язык структурированных запросов SQL (Structured Query Language) и его место в сфере доступа к информации в реляционных базах данных. Структура и основные типы данных языка. Синтаксис и семантика главных операторов SQL, последние стандарты языка.
реферат , добавлен 29.03.2012
Теоретические сведения и основные понятия баз данных. Системы управления базами данных: состав, структура, безопасность, режимы работы, объекты. Работа с базами данных в OpenOffice.Org BASE: создание таблиц, связей, запросов с помощью мастера запросов.
курсовая работа , добавлен 28.04.2011
Различия между существующими диалектами SQL. Стандартизация языка SQL. Концепция баз данных. Эффективность организации данных. Структура языка SQL. Приближенные числовые типы. Интервальный тип данных. Обработка сложно структурированной информации.
курсовая работа , добавлен 29.05.2014
Общие сведения о системах управления базами данных MS Access. Использование языка QBE для создания запросов на выборку данных. Параметрические и перекрестные запросы. Запросы с автоподстановкой, на выборку дубликатов и записей, не имеющих соответствия.
курсовая работа , добавлен 03.06.2015
Проектирование реляционной базы данных с помощью прикладного программного средства MS ACCESS. Описания особенностей использования запросов для извлечения, изменения и удаления информации из базы данных. Характеристика структуры интерфейса пользователя.
курсовая работа , добавлен 19.11.2012
Анализ предметной области с использованием моделей методологии ARIS и разработка ER-диаграммы. Описание входной и выходной информации для проектирования реляционной базы данных. Разработка управляющих запросов и связей между ними с помощью языка SQL.
Вредоносное ПО (malware) - это назойливые или опасные программы,...

Лучшие программы для восстановления данных с любых носителей информации....

Здравствуйте.Одна из самых распространенных причин, по которым тормозит...