मालवेअर हे अनाहूत किंवा धोकादायक प्रोग्राम आहेत जे...


cURL आहे विशेष साधन, जे URL वाक्यरचना वापरून फायली आणि डेटा हस्तांतरित करण्यासाठी डिझाइन केलेले आहे. हे तंत्रज्ञान HTTP, FTP, TELNET आणि इतर अनेक प्रोटोकॉल्सना समर्थन देते. cURL मूलतः एक साधन म्हणून डिझाइन केले होते कमांड लाइन. आमच्यासाठी सुदैवाने, cURL लायब्ररी भाषेद्वारे समर्थित आहे PHP प्रोग्रामिंग. या लेखात आम्ही कर्ल आणि कव्हरची काही प्रगत वैशिष्ट्ये पाहू व्यावहारिक वापर PHP वापरून ज्ञान मिळवले.
खरं तर, अनेक आहेत पर्यायी मार्गवेब पृष्ठ सामग्रीचे नमुने. बर्याच बाबतीत, मुख्यतः आळशीपणामुळे, मी साधे वापरले PHP फंक्शन्सकर्ल ऐवजी:
$content = file_get_contents("http://www.nettuts.com"); // किंवा $lines = फाइल("http://www.nettuts.com"); // किंवा वाचा फाइल("http://www.nettuts.com");
तथापि, या फंक्शन्समध्ये अक्षरशः लवचिकता नसते आणि त्रुटी हाताळणी इत्यादींच्या बाबतीत मोठ्या संख्येने कमतरता असतात. शिवाय, अशी काही कार्ये आहेत जी तुम्ही यासह सोडवू शकत नाही मानक कार्ये: कुकीजसह परस्परसंवाद, प्रमाणीकरण, फॉर्म सबमिशन, फाइल अपलोड इ.
cURL ही एक शक्तिशाली लायब्ररी आहे जी अनेकांना समर्थन देते विविध प्रोटोकॉल, पर्याय आणि प्रदान तपशीलवार माहितीओ URL विनंतीओह.
// 1. आरंभीकरण $ch = curl_init(); // 2. url curl_setopt($ch, CURLOPT_URL, "http://www.nettuts.com") सह पॅरामीटर्स निर्दिष्ट करा; curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_HEADER, 0); // 3. परिणाम म्हणून HTML मिळवा $output = curl_exec($ch); // 4. कनेक्शन बंद करा curl_close($ch);
पायरी # 2 (म्हणजे, curl_setopt()) या लेखात इतर सर्व चरणांपेक्षा जास्त चर्चा केली जाईल, कारण या टप्प्यावर, आपल्याला माहित असणे आवश्यक असलेल्या सर्व सर्वात मनोरंजक आणि उपयुक्त गोष्टी घडतात. CURL मध्ये मोठ्या संख्येने भिन्न पर्याय आहेत जे सर्वात काळजीपूर्वक URL विनंती कॉन्फिगर करण्यास सक्षम होण्यासाठी निर्दिष्ट करणे आवश्यक आहे. आम्ही संपूर्ण यादीचा विचार करणार नाही, परंतु या धड्यासाठी मला जे आवश्यक आणि उपयुक्त वाटते त्यावरच लक्ष केंद्रित करू. हा विषय तुम्हाला स्वारस्य असल्यास तुम्ही स्वतः इतर सर्व गोष्टींचा अभ्यास करू शकता.
याव्यतिरिक्त, आपण देखील वापरू शकता सशर्त विधानेयशस्वीतेसाठी ऑपरेशन तपासण्यासाठी:
// ... $आउटपुट = curl_exec($ch); जर ($आउटपुट === असत्य) ( echo "cURL त्रुटी: " . curl_error($ch); ) // ...
येथे मी तुम्हाला स्वतःसाठी लक्षात घेण्यास सांगतो महत्वाचा मुद्दा: आपण तुलना करण्यासाठी “== असत्य” ऐवजी “=== असत्य” वापरावे. ज्यांना माहिती नाही त्यांच्यासाठी, हे आम्हाला रिक्त परिणाम आणि बुलियन व्हॅल्यू असत्य यातील फरक ओळखण्यास मदत करेल, जे त्रुटी दर्शवेल.
दुसरी अतिरिक्त पायरी म्हणजे कर्ल विनंती कार्यान्वित झाल्यानंतर त्याबद्दल डेटा प्राप्त करणे.
// ... curl_exec($ch); $info = curl_getinfo($ch); इको "घेतले". $माहिती["एकूण_वेळ"] . "url साठी सेकंद". $info["url"]; //…
परत केलेल्या ॲरेमध्ये खालील माहिती आहे:
या पहिल्या उदाहरणामध्ये, आम्ही कोड लिहू जो आधारित URL पुनर्निर्देशने शोधू शकतो विविध सेटिंग्जब्राउझर उदाहरणार्थ, काही वेबसाइट ब्राउझर पुनर्निर्देशित करतात सेल फोन, किंवा इतर कोणतेही उपकरण.
आम्ही वापरकर्त्याच्या ब्राउझर नावासह आमचे आउटगोइंग HTTP शीर्षलेख परिभाषित करण्यासाठी CURLOPT_HTTPHEADER पर्याय वापरणार आहोत आणि उपलब्ध भाषा. अखेरीस आम्ही हे निर्धारित करण्यात सक्षम होऊ की कोणत्या साइट आम्हाला वेगवेगळ्या URL वर पुनर्निर्देशित करत आहेत.
// URL $urls = array("http://www.cnn.com", "http://www.mozilla.com", "http://www.facebook.com" ची चाचणी करा; // चाचणी ब्राउझर $browsers = array("standard" => array ("user_agent" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5 .6 (.NET CLR 3.5.30729)", "language" => "en-us,en;q=0.5"), "iphone" => array ("user_agent" => "Mozilla/5.0 (iPhone; U ; CPU जसे Mac OS X => "Mozilla/4.0 (सुसंगत; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)", "language" => "fr,fr-FR;q=0.5")); foreach ($urls $url म्हणून) ( प्रतिध्वनी "URL: $url\n"; foreach ($browsers $test_name => $browser) ( $ch = curl_init(); // url curl_setopt($ch, CURLOPT_URL) निर्दिष्ट करा , $url); // ब्राउझर curl_setopt($ch, CURLOPT_HTTPHEADER, array("User-Agent: ($browser["user_agent"])", "Accept-Language: ($browser["language"] साठी हेडर निर्दिष्ट करा )" )); // आम्हाला पृष्ठ सामग्रीची आवश्यकता नाही curl_setopt($ch, CURLOPT_NOBODY, 1); // आम्हाला HTTP शीर्षलेख curl_setopt($ch, CURLOPT_HEADER, 1); // आउटपुटऐवजी परिणाम परत करणे आवश्यक आहे curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $output = curl_close($ch); , $matches) ( प्रतिध्वनी " $test_name: $matches\n" वर पुनर्निर्देशित करते; ) इतर ( प्रतिध्वनी "$test_name: कोणतेही पुनर्निर्देशन नाही\n"; ) ) प्रतिध्वनी "\n\n" )
प्रथम आम्ही सूचित करतो URL ची सूचीज्या साइट्स आम्ही तपासू. अधिक स्पष्टपणे, आम्हाला या साइट्सचे पत्ते आवश्यक आहेत. पुढे आपल्याला या प्रत्येक URL ची चाचणी करण्यासाठी ब्राउझर सेटिंग्ज परिभाषित करण्याची आवश्यकता आहे. यानंतर, आपण एक लूप वापरू ज्यामध्ये आपण प्राप्त केलेल्या सर्व परिणामांमधून जाऊ.
CURL सेटिंग्ज सेट करण्यासाठी आम्ही या उदाहरणात जी युक्ती वापरतो ती आम्हाला पृष्ठाची सामग्री नाही तर फक्त HTTP शीर्षलेख ($output मध्ये संग्रहित) मिळविण्याची अनुमती देईल. पुढे, एक साधा regex वापरून, प्राप्त शीर्षलेखांमध्ये “स्थान:” ही स्ट्रिंग उपस्थित होती की नाही हे आपण निर्धारित करू शकतो.
जेव्हा तुम्ही धावता हा कोड, तुम्हाला खालील परिणामासारखे काहीतरी मिळाले पाहिजे:
तयार करताना विनंती मिळवाप्रसारित केलेला डेटा URL वर "क्वेरी स्ट्रिंग" द्वारे पास केला जाऊ शकतो. उदाहरणार्थ, जेव्हा तुम्ही Google वर शोधता, तेव्हा शोध संज्ञा मध्ये स्थित असतात पत्ता लिहायची जागानवीन URL:
http://www.google.com/search?q=ruseller
अनुकरण करण्यासाठी ही विनंती, तुम्हाला कर्ल सुविधा वापरण्याची गरज नाही. आळस तुमच्यावर पूर्णपणे मात करत असल्यास, परिणाम मिळविण्यासाठी “file_get_contents()” फंक्शन वापरा.
पण गोष्ट अशी आहे की काही HTML फॉर्म सबमिट करतात पोस्ट विनंती s या फॉर्ममधील डेटा शरीराद्वारे वाहून नेला जातो HTTP विनंती, आणि मागील केस प्रमाणे नाही. उदाहरणार्थ, जर तुम्ही फोरमवर एक फॉर्म भरला आणि शोध बटणावर क्लिक केले, तर बहुधा POST विनंती केली जाईल:
http://codeigniter.com/forums/do_search/
आपण लिहू शकतो PHP स्क्रिप्ट, जे या प्रकारच्या विनंती URL चे अनुकरण करू शकते. प्रथम स्वीकारण्यासाठी आणि प्रदर्शित करण्यासाठी एक साधी फाइल तयार करूया पोस्ट डेटा. याला post_output.php म्हणू या:
Print_r($_POST);
मग आम्ही कर्ल विनंती करण्यासाठी PHP स्क्रिप्ट तयार करतो:
$url = "http://localhost/post_output.php"; $post_data = ॲरे ("foo" => "bar", "query" => "Nettuts", "कृती" => "सबमिट करा"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // सूचित करा की आमच्याकडे POST विनंती curl_setopt($ch, CURLOPT_POST, 1); // curl_setopt ($ch, CURLOPT_POSTFIELDS, $post_data) व्हेरिएबल्स जोडा; $आउटपुट = curl_exec($ch); curl_close($ch); echo $output;
जेव्हा तुम्ही ही स्क्रिप्ट चालवता तेव्हा तुम्हाला असा परिणाम मिळावा:
अशाप्रकारे, POST विनंती post_output.php स्क्रिप्टवर पाठवली गेली, जी सुपरग्लोबल $_POST ॲरे आउटपुट करते, ज्याची सामग्री आम्ही cURL वापरून मिळवली.
प्रथम, ती तयार करण्यासाठी फाईल तयार करूया आणि ती upload_output.php फाईलवर पाठवू:
Print_r($_FILES);
आणि येथे स्क्रिप्ट कोड आहे जो वरील कार्यक्षमता करतो:
$url = "http://localhost/upload_output.php"; $post_data = array ("foo" => "bar", // फाइल अपलोड करण्यासाठी "upload" => "@C:/wamp/www/test.zip"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $आउटपुट = curl_exec($ch); curl_close($ch); echo $output;
जेव्हा तुम्हाला फाइल अपलोड करायची असेल, तेव्हा तुम्हाला फक्त ती सामान्य पोस्ट व्हेरिएबल म्हणून पास करायची आहे, त्याच्या आधी @ चिन्ह असेल. जेव्हा तुम्ही लिखित स्क्रिप्ट चालवता तेव्हा तुम्हाला खालील परिणाम मिळतील:

सर्वात एक शक्ती cURL ही "एकाधिक" cURL हँडलर तयार करण्याची क्षमता आहे. हे तुम्हाला एकाच वेळी आणि असिंक्रोनस एकाधिक URL चे कनेक्शन उघडण्याची अनुमती देते.
क्लासिक आवृत्ती मध्ये cURL विनंतीस्क्रिप्ट कार्यान्वित करणे निलंबित केले आहे आणि स्क्रिप्ट चालू ठेवण्यापूर्वी URL विनंती ऑपरेशन पूर्ण होण्याची प्रतीक्षा करते. तुम्हाला संपूर्ण URL सह संवाद साधण्याचा इरादा असल्यास, यामुळे वेळेची लक्षणीय गुंतवणूक होईल, कारण क्लासिक आवृत्तीमध्ये तुम्ही एकावेळी एका URL सह कार्य करू शकता. तथापि, आम्ही त्याचे निराकरण करू शकतो ही परिस्थिती, विशेष हँडलर वापरून.
मी php.net वरून घेतलेला उदाहरण कोड पाहू:
// अनेक cURL संसाधने तयार करा $ch1 = curl_init(); $ch2 = curl_init(); // URL आणि इतर पॅरामीटर्स निर्दिष्ट करा curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/"); curl_setopt($ch1, CURLOPT_HEADER, 0); curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/"); curl_setopt($ch2, CURLOPT_HEADER, 0); // एकाधिक cURL हँडलर तयार करा $mh = curl_multi_init(); //अनेक हँडलर जोडा curl_multi_add_handle($mh,$ch1); curl_multi_add_handle($mh,$ch2); $active = शून्य; // कार्यान्वित करा ( $mrc = curl_multi_exec($mh, $active); ) तर ($mrc == CURLM_CALL_MULTI_PERFORM); ($active && $mrc == CURLM_OK) ( जर (curl_multi_select($mh) != -1) ( do ( $mrc = curl_multi_exec($mh, $active); ) तर ($mrc == CURLM_CALL_MULTI_PERFORM); ) // curl_multi_remove_handle($mh, $ch1); curl_multi_remove_handle($mh, $ch2); curl_multi_close($mh);
कल्पना अशी आहे की तुम्ही एकाधिक कर्ल हँडलर वापरू शकता. साध्या लूपचा वापर करून, कोणत्या विनंत्या अद्याप पूर्ण झाल्या नाहीत याचा मागोवा ठेवू शकता.
या उदाहरणात दोन मुख्य लूप आहेत. पहिला do-while लूप curl_multi_exec() फंक्शन कॉल करते. हे कार्य अवरोधित करण्यायोग्य नाही. हे शक्य तितक्या वेगाने चालते आणि विनंतीची स्थिती परत करते. जोपर्यंत परत केलेले मूल्य 'CURLM_CALL_MULTI_PERFORM' स्थिर आहे, तोपर्यंत याचा अर्थ कार्य अद्याप पूर्ण झालेले नाही (उदाहरणार्थ, मध्ये हा क्षणपाठवणे चालू आहे http शीर्षलेख URL मध्ये); म्हणूनच जोपर्यंत आम्हाला वेगळा निकाल मिळत नाही तोपर्यंत आम्ही हे परतावा मूल्य तपासत राहतो.
पुढील लूपमध्ये आपण $active = "true" व्हेरिएबल असताना स्थिती तपासू. हे curl_multi_exec() फंक्शनचे दुसरे पॅरामीटर आहे. जोपर्यंत विद्यमान बदल सक्रिय आहेत तोपर्यंत या व्हेरिएबलचे मूल्य "सत्य" असेल. पुढे आपण curl_multi_select() फंक्शन म्हणतो. प्रतिसाद प्राप्त होईपर्यंत, किमान एक सक्रिय कनेक्शन असताना त्याची अंमलबजावणी "अवरोधित" केली जाते. जेव्हा असे होते, तेव्हा आम्ही क्वेरी कार्यान्वित करणे सुरू ठेवण्यासाठी मुख्य लूपवर परत येतो.
आता आपण जे शिकलो ते एका उदाहरणावर लागू करूया जे खरोखर उपयोगी पडेल मोठ्या प्रमाणातलोकांचे.
यासह ब्लॉगची कल्पना करा एक मोठी रक्कमपोस्ट आणि मेसेज, त्यांपैकी प्रत्येकामध्ये लिंक्स असतात बाह्य इंटरनेटसंसाधने यापैकी काही लिंक्स विविध कारणेआधीच "मृत" असू शकते. कदाचित पृष्ठ हटविले गेले असेल किंवा साइट कदाचित कार्य करत नसेल.
आम्ही एक स्क्रिप्ट तयार करणार आहोत जी सर्व लिंक्सचे विश्लेषण करेल आणि लोड न होणाऱ्या वेबसाइट्स आणि 404 पृष्ठे शोधेल आणि नंतर आम्हाला तपशीलवार अहवाल देईल.
मी लगेच सांगेन की हे वर्डप्रेससाठी प्लगइन तयार करण्याचे उदाहरण नाही. आमच्या चाचण्यांसाठी हे एक उत्तम चाचणी मैदान आहे.
चला शेवटी सुरुवात करूया. प्रथम आपल्याला डेटाबेसमधून सर्व दुवे आणण्याची आवश्यकता आहे:
// कॉन्फिगरेशन $db_host = "स्थानिक होस्ट"; $db_user = "रूट"; $db_pass = ""; $db_name = "वर्डप्रेस"; $excluded_domains = array("localhost", "www.mydomain.com"); $max_connections = 10; // व्हेरिएबल्सचे आरंभीकरण $url_list = ॲरे(); $working_urls = ॲरे(); $dead_urls = ॲरे(); $not_found_urls = ॲरे(); $active = शून्य; // MySQL शी कनेक्ट करा जर (!mysql_connect($db_host, $db_user, $db_pass)) ( die("कनेक्ट करू शकलो नाही: " . mysql_error()); ) जर (!mysql_select_db($db_name)) ( die("Could db निवडू नका: " . mysql_error()); ) // $q = "wp_posts मधून post_content निवडा जिथे "%href=%" आणि post_status = "प्रकाशित करा" आणि post_type = "पोस्ट" या लिंक्स असलेल्या सर्व प्रकाशित पोस्ट निवडा "; $r = mysql_query($q) किंवा die(mysql_error()); तर ($d = mysql_fetch_assoc($r)) (// वापरून दुवे आणा नियमित अभिव्यक्तीजर (preg_match_all("!href=\"(.*?)\"!", $d["post_content"], $matches)) ( foreach ($ matches as $url) ( $tmp = parse_url($url) ; जर (in_array($tmp["host"], $excluded_domains) ( continue; ) $url_list = $url; ) // $url_list = array_values(array_unique($url_list)); जर (!$url_list) ( die("तपासण्यासाठी URL नाही"); )
प्रथम, आम्ही डेटाबेससह परस्परसंवादासाठी कॉन्फिगरेशन डेटा व्युत्पन्न करतो, त्यानंतर आम्ही डोमेनची सूची लिहितो जी चेकमध्ये सहभागी होणार नाहीत ($excluded_domains). आम्ही आमच्या स्क्रिप्टमध्ये ($max_connections) वापरणार असलेल्या कमाल एकाचवेळी जोडण्यांची संख्या दर्शविणारी संख्या देखील परिभाषित करतो. त्यानंतर आम्ही डेटाबेसमध्ये सामील होतो, लिंक्स असलेल्या पोस्ट्सची निवड करतो आणि त्यांना ॲरे ($url_list) मध्ये जमा करतो.
खालील कोड थोडासा क्लिष्ट आहे, त्यामुळे सुरुवातीपासून ते शेवटपर्यंत चाला:
// 1. एकाधिक हँडलर $mh = curl_multi_init(); // 2. ($i = 0; $i. साठी URL चा संच जोडा< $max_connections; $i++) { add_url_to_multi_handle($mh, $url_list); } // 3. инициализация выполнения do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 4. основной цикл while ($active && $mrc == CURLM_OK) { // 5. если всё прошло успешно if (curl_multi_select($mh) != -1) { // 6. делаем дело do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 7. если есть инфа? if ($mhinfo = curl_multi_info_read($mh)) { // это значит, что запрос завершился // 8. извлекаем инфу $chinfo = curl_getinfo($mhinfo["handle"]); // 9. мёртвая ссылка? if (!$chinfo["http_code"]) { $dead_urls = $chinfo["url"]; // 10. 404? } else if ($chinfo["http_code"] == 404) { $not_found_urls = $chinfo["url"]; // 11. рабочая } else { $working_urls = $chinfo["url"]; } // 12. чистим за собой curl_multi_remove_handle($mh, $mhinfo["handle"]); // в случае зацикливания, закомментируйте हा कॉल curl_close($mhinfo["हँडल"]); // 13. नवीन url जोडा आणि कार्य करणे सुरू ठेवा जर (add_url_to_multi_handle($mh, $url_list)) ( do ( $mrc = curl_multi_exec($mh, $active); ) तर ($mrc == CURLM_CALL_MULTI_PERFORM); ) ) ) ) // 14. पूर्णता curl_multi_close($mh); echo "==डेड URLs==\n"; echo implode("\n",$dead_urls) . "\n\n"; echo "==404 URLs==\n"; echo implode("\n",$not_found_urls) . "\n\n"; echo "==कार्यरत URLs==\n"; echo implode("\n",$working_urls); फंक्शन add_url_to_multi_handle($mh, $url_list) ( static $index = 0; // जर आमच्याकडे अधिक url असतील ज्या पुनर्प्राप्त करणे आवश्यक आहे जर ($url_list[$index]) ( // new curl handler $ch = curl_init(); // url curl_setopt($ch, CURLOPT_URL, $url_list[$index]); निर्दिष्ट करा $mh, $ch);
येथे मी सर्वकाही तपशीलवार सांगण्याचा प्रयत्न करेन. सूचीतील संख्या टिप्पणीमधील संख्यांशी संबंधित आहेत.
मी वापरले ही स्क्रिप्टमाझ्या ब्लॉगवर (काही तुटलेल्या दुव्यांसह, जे मी त्याच्या कार्याची चाचणी घेण्यासाठी हेतुपुरस्सर जोडले आहे) आणि खालील परिणाम मिळाले:

माझ्या बाबतीत, स्क्रिप्टला 40 URL मध्ये क्रॉल करण्यासाठी 2 सेकंदांपेक्षा थोडा कमी वेळ लागला. अधिक काम करताना उत्पादकता वाढ लक्षणीय आहे मोठी रक्कम URL पत्ते. तुम्ही एकाच वेळी दहा कनेक्शन उघडल्यास, स्क्रिप्ट दहापट वेगाने कार्यान्वित करू शकते.
चालू असल्यास URL पत्तातुमच्याकडे HTTP प्रमाणीकरण असल्यास, तुम्ही खालील स्क्रिप्ट सहजपणे वापरू शकता:
$url = "http://www.somesite.com/members/"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // वापरकर्तानाव आणि पासवर्ड निर्दिष्ट करा curl_setopt($ch, CURLOPT_USERPWD, "myusername:mypassword"); // जर पुनर्निर्देशनाला परवानगी असेल तर curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // नंतर आमचा डेटा cURL curl_setopt($ch, CURLOPT_UNRESTRICTED_AUTH, 1) मध्ये जतन करा; $आउटपुट = curl_exec($ch); curl_close($ch);
PHP मध्ये FTP सह कार्य करण्यासाठी लायब्ररी देखील आहे, परंतु येथे CURL साधने वापरण्यापासून काहीही प्रतिबंधित करत नाही:
// फाइल उघडा $file = fopen("/path/to/file", "r"); // url मध्ये खालील सामग्री असावी $url = "ftp://username: [ईमेल संरक्षित]:21/path/to/new/file"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_UPLOAD, 1); curl_setopt($ch, CURLOPT_INFILE, $fp); curl_close($ch);
तुम्ही तुमची URL विनंती प्रॉक्सीद्वारे करू शकता:
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://www.example.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // पत्ता निर्दिष्ट करा curl_setopt($ch, CURLOPT_PROXY, "11.11.11.11:8080"); // जर तुम्हाला वापरकर्तानाव आणि पासवर्ड प्रदान करायचा असेल curl_setopt($ch, CURLOPT_PROXYUSERPWD,"user:pass"); $आउटपुट = curl_exec($ch); curl_close($ch);
एक फंक्शन निर्दिष्ट करणे देखील शक्य आहे जे cURL विनंती पूर्ण होण्यापूर्वीच ट्रिगर केले जाईल. उदाहरणार्थ, प्रतिसाद सामग्री लोड होत असताना, तुम्ही डेटा पूर्णपणे लोड होण्याची वाट न पाहता वापरणे सुरू करू शकता.
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://net.tutsplus.com"); curl_setopt($ch, CURLOPT_WRITEFUNCTION,"progress_function"); curl_exec($ch); curl_close($ch); फंक्शन प्रोग्रेस_फंक्शन($ch,$str) ( echo $str; रिटर्न strlen($str); )
यासारख्या फंक्शनने स्ट्रिंगची लांबी परत करणे आवश्यक आहे, जी एक आवश्यकता आहे.
आज आम्ही शिकलो की तुम्ही तुमच्या मध्ये cURL लायब्ररी कशी वापरू शकता स्वार्थी हेतूने. मला आशा आहे की तुम्हाला हा लेख आवडला असेल.
धन्यवाद! तुमचा दिवस चांगला जावो!
तर, चला सुरुवात करूया. प्रथम, आपल्याला नेमके काय करायचे आहे ते ठरवूया. जेव्हा तुम्ही लिंकवर क्लिक करता तेव्हा क्लिकची संख्या मोजण्यासाठी, आम्हाला क्लिक मोजण्यासाठी एक विशेष स्क्रिप्ट वापरावी लागते आणि नंतर अभ्यागताला त्याला स्वारस्य असलेली माहिती प्रदान करावी लागते (पुनर्निर्देशित आवश्यक फाइल). तत्वतः, अनुक्रम (क्लिक करून आणि माहिती प्रदर्शित करून) उलट केला जाऊ शकतो, परंतु लक्षात ठेवा की जर काउंटरचा वापर फाइल डाउनलोड मोजण्यासाठी केला जात असेल, तर फाइल डाउनलोड केल्यानंतर स्क्रिप्ट कार्यान्वित करण्यासाठी, तुम्हाला लिहावे लागेल. एक विशेष फाइल डाउनलोडर स्क्रिप्ट. तुला कशाला गरज आहे अनावश्यक समस्या? ऑपरेशनचे समान तत्त्व भेट काउंटरवर लागू होईल. या प्रकरणात, पृष्ठ लोडिंगला गती देण्यासाठी, आपण पुनर्निर्देशित न करता करू शकता आणि लोडिंग पृष्ठामध्ये फक्त काउंटर कोड घालू शकता.
असे दिसते की आम्ही ते शोधून काढले आहे, बरोबर? बरं, आता आमच्या सर्व कल्पना अंमलात आणण्यासाठी साध्या कोडचे पृथक्करण सुरू करूया. उदाहरणाच्या साधेपणासाठी, आणि स्क्रिप्ट कोणत्याही होस्टिंगवर कार्य करू शकते म्हणून, आम्ही डेटा फाइलमध्ये संग्रहित करू.
$f = fopen(" stat.dat","a+"); कळप($f ,LOCK_EX); $count =fread($f,100); @$count++; ftruncate($f ,0); fwrite($f ,$count); फ्लश($f); कळप($f ,LOCK_UN); fclose($f); |
होय, तुम्ही ते बरोबर वाचले आहे, ही संपूर्ण स्क्रिप्ट आहे. आता ते काय आणि कसे कार्य करते ते शोधूया.
कोडची पहिली ओळ आहे $f =fopen(" stat.dat","a+"); आम्ही फाइल उघडतो stat.datवाचन आणि लेखनासाठी, आम्ही ते फाइल व्हेरिएबल $f शी जोडतो. ही फाईल आहे जी काउंटरच्या स्थितीबद्दल डेटा संग्रहित करेल. योग्य ऑपरेशनसाठी, मी तुम्हाला या फाईलसाठी 777 किंवा तत्सम पूर्ण वाचन आणि लेखन प्रवेशासह प्रवेश अधिकार सेट करण्याचा सल्ला देतो.
पुढील ओळ flock($f ,LOCK_EX) आहे; स्क्रिप्ट कार्य करण्यासाठी खूप महत्वाचे आहे. ती काय करत आहे? हे स्क्रिप्ट चालू असताना (किंवा ती काढून टाकेपर्यंत) इतर स्क्रिप्ट्स किंवा याच्या प्रतींसाठी फाइलमध्ये प्रवेश अवरोधित करते. हे इतके महत्त्वाचे का आहे? चला एका परिस्थितीची कल्पना करूया: ज्या क्षणी user1 क्लिक मोजणी स्क्रिप्ट लाँच करणाऱ्या लिंकवर क्लिक करतो, तेव्हा user2 त्याच लिंकवर क्लिक करतो, त्याच स्क्रिप्टची प्रत लाँच करतो. तुम्ही खाली पाहाल त्याप्रमाणे, user1 ने लाँच केलेली स्क्रिप्ट कोणत्या टप्प्यावर आहे यावर अवलंबून, user2 ने लॉन्च केलेली स्क्रिप्ट आणि त्याच्या कॉपीच्या समांतर चालणारी स्क्रिप्ट काउंटरला शून्यावर रीसेट करू शकते. जवळजवळ सर्व नवशिक्या PHP प्रोग्रामर समान काउंटर तयार करताना ही चूक करतात. आता, मला वाटते की आम्हाला फाइलमध्ये प्रवेश का अवरोधित करण्याची आवश्यकता आहे हे स्पष्ट आहे - इन या प्रकरणात user2 ने लाँच केलेली स्क्रिप्ट user1 ने लाँच केलेली स्क्रिप्ट पूर्ण होईपर्यंत प्रतीक्षा करेल (यामुळे पेज लोड होण्याचा वेग कमी होईल याची भीती बाळगू नका - अगदी धीमे सर्व्हर देखील ही स्क्रिप्ट एका सेकंदाच्या शंभरावा भागामध्ये कार्यान्वित करतात).
कोडच्या तिसऱ्या ओळीसह $count =fread($f ,100); सर्व स्पष्ट. आपण काउंटर व्हॅल्यू $count व्हेरिएबलमध्ये वाचतो.
आता आपल्याला फाइलमध्ये अपडेट केलेला डेटा लिहायचा आहे. हे करण्यासाठी, तुम्हाला प्रथम ftruncate($f ,0) फाइल साफ करावी लागेल; मी ज्याबद्दल बोललो त्या काउंटर रीसेटिंगसह धोकादायक परिस्थिती येथेच उद्भवू शकते. तथापि, आम्ही फाईल लॉकिंग वापरतो, त्यामुळे घाबरण्याचे काहीच नाही.
काउंटर मूल्य fwrite($f ,$count ) बद्दल अपडेट केलेला डेटा लिहा;
सुरक्षित राहण्यासाठी, आम्ही या फाईल fflush($f) साठी I/O बफर सक्तीने साफ करतो;
फाइल फ्लॉकमधून लॉक काढा($f ,LOCK_UN); खरं तर, तुम्हाला ते काढण्याची गरज नाही - फाइल बंद केल्यावर ती आपोआप काढून टाकली जाते. तथापि, उदाहरणाच्या पूर्णतेसाठी, मी तरीही ते लिहिले.
फाइल बंद करणे fclose($f); आवश्यक कार्य देखील नाही कारण स्क्रिप्टद्वारे उघडलेल्या सर्व फाइल्स, पूर्ण झाल्यानंतर, आपोआप बंद होतात. परंतु पुन्हा, उदाहरणाच्या पूर्णतेसाठी... =) याव्यतिरिक्त, स्क्रिप्ट येथे संपत नसल्यास, आणि आपल्याला यापुढे फाइलसह कार्य करण्याची आवश्यकता नसल्यास, फाइल त्वरित बंद करण्याची शिफारस केली जाते.
ठीक आहे आता सर्व संपले आहे. जसे आपण पाहू शकता, हे सर्व कठीण नाही. आता भेटींची संख्या मोजण्यासाठी, फक्त हा कोड पृष्ठावर पेस्ट करा. आणि जर तुम्हाला फाइलच्या डाउनलोड्सची संख्या मोजायची असेल, तर हा कोड वेगळ्या PHP फाइलमध्ये घाला, फाइलच्या नावातील दुवा या स्क्रिप्टच्या दुव्यासह पुनर्स्थित करा आणि डाउनलोड फाइलच्या शेवटी एक पुनर्निर्देशन जोडा. पटकथा. हे PHP मध्ये उत्तम प्रकारे केले जाते: हेडर(" स्थान:/download_dir/file_to_download.rar");
अरे हो. तुम्हाला काउंटर मूल्य देखील प्रदर्शित करणे आवश्यक आहे, अन्यथा मोजण्यात काही अर्थ नाही =). अर्थात, आम्ही फाइलमधून मूल्ये घेतो. आपण हे काउंटरच्या उदाहरणाप्रमाणे करू शकता:
| $f = fopen(" stat.dat","a+"); कळप($f ,LOCK_EX); $count =fread($f ,100); कळप($f ,LOCK_UN); fclose($f); इको "डाउनलोड्स/क्लिक्सची संख्या: $count"; |
डाउनलोड केलेली फाइल डबल क्लिक करून चालवा (तुमच्याकडे व्हर्च्युअल मशीन असणे आवश्यक आहे).
[विभाग विकासाधीन]
[विभाग विकासाधीन]
[विभाग विकासाधीन]
प्रोग्रामसह कार्य करणे अत्यंत सोपे आहे. फक्त वेबसाइट पत्ता प्रविष्ट करा आणि ENTER दाबा.
खालील स्क्रीनशॉट दर्शवितो की साइट तीन प्रकारच्या SQL इंजेक्शन्ससाठी असुरक्षित आहे (त्यांच्याबद्दलची माहिती खालच्या उजव्या कोपर्यात दर्शविली आहे). इंजेक्शनच्या नावांवर क्लिक करून तुम्ही वापरलेली पद्धत बदलू शकता:
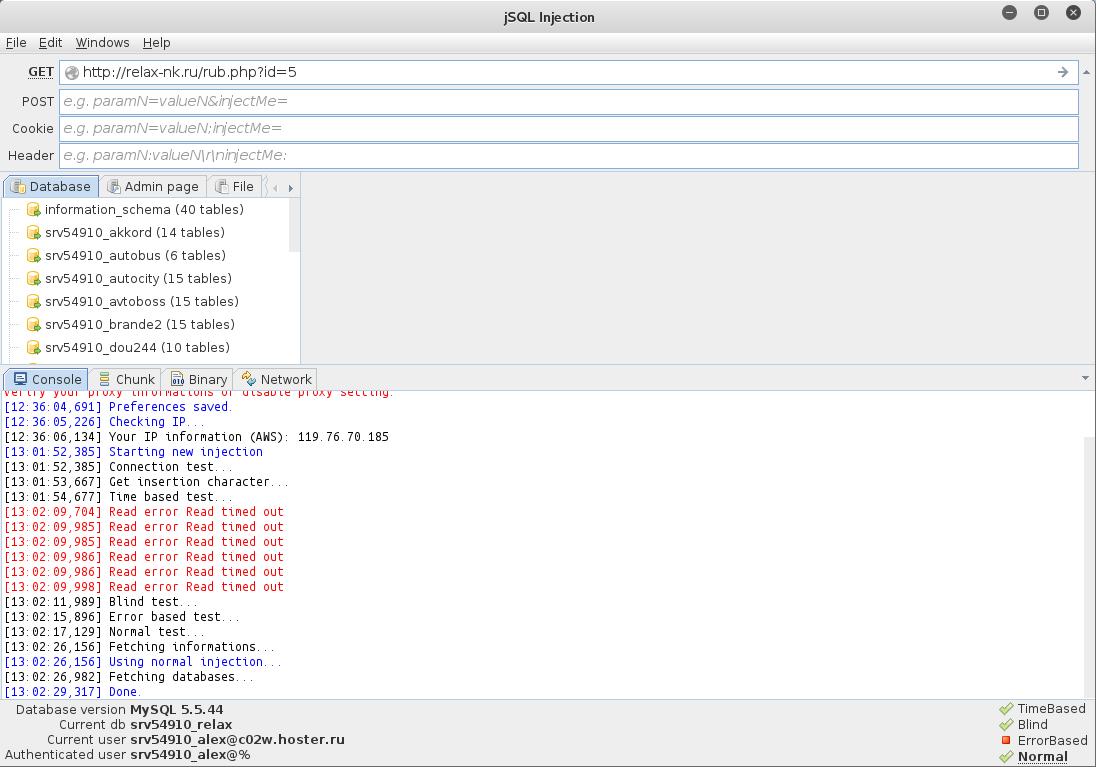
तसेच, विद्यमान डेटाबेस आम्हाला आधीच प्रदर्शित केले गेले आहेत.
आपण प्रत्येक सारणीची सामग्री पाहू शकता:
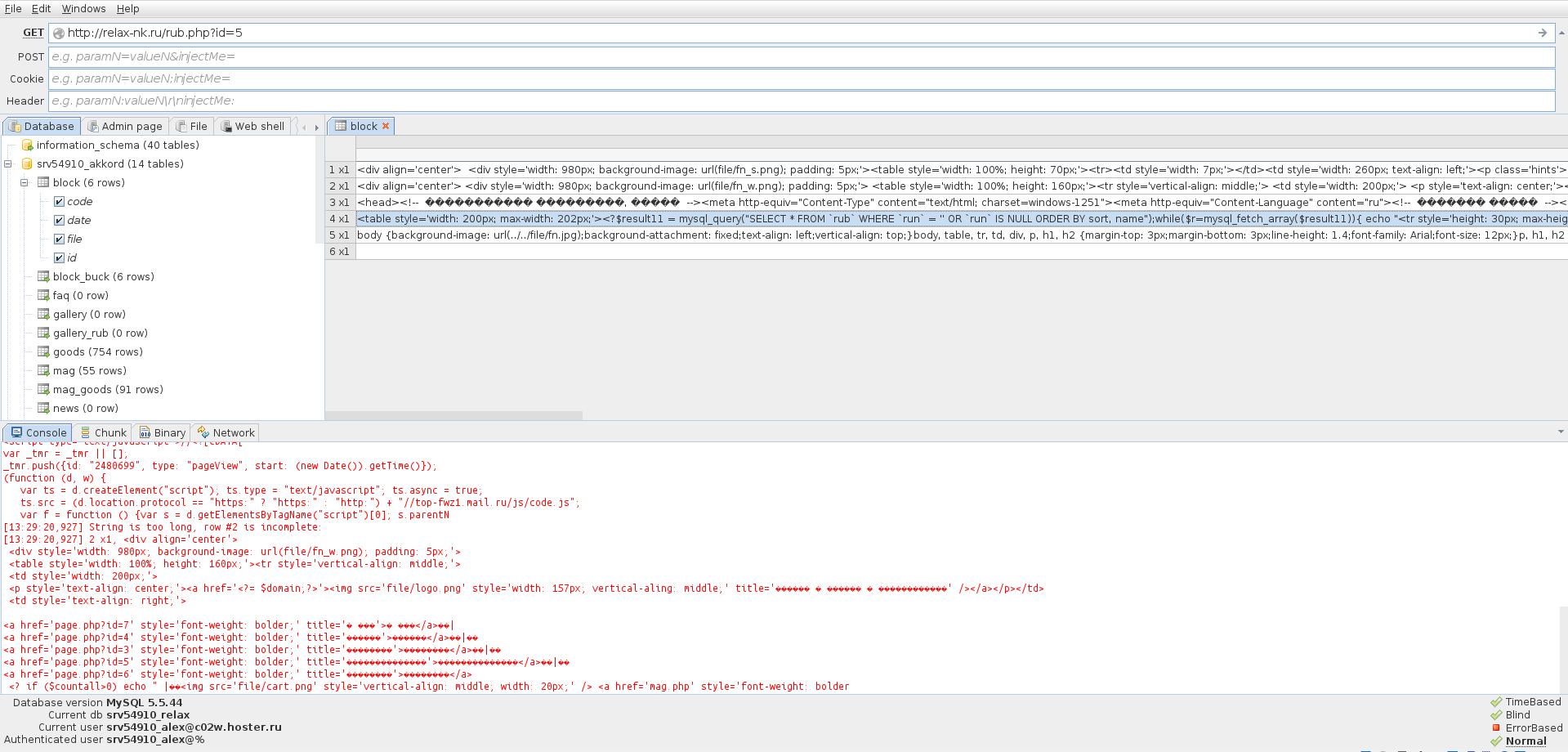
सामान्यतः, टेबलांबद्दल सर्वात मनोरंजक गोष्ट म्हणजे प्रशासक क्रेडेन्शियल्स.
जर तुम्ही भाग्यवान असाल आणि तुम्हाला प्रशासकाचा डेटा सापडला तर आनंद करणे खूप लवकर आहे. हा डेटा कुठे एंटर करायचा हे तुम्हाला अजूनही ॲडमिन पॅनल शोधण्याची गरज आहे.
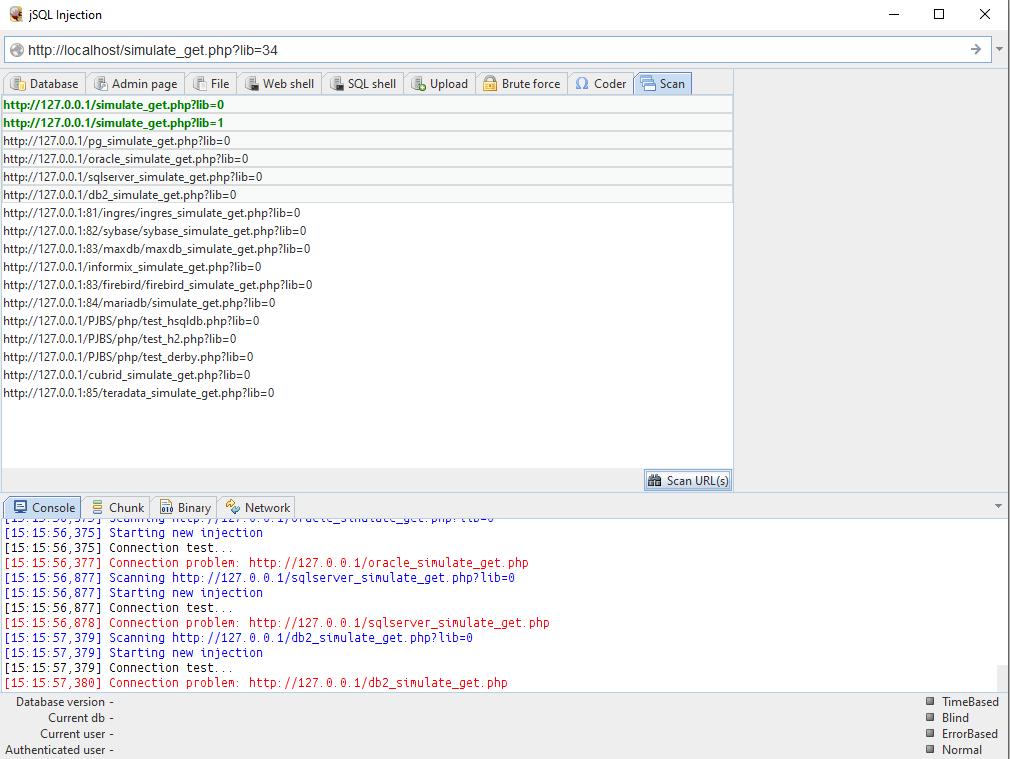
हे करण्यासाठी, पुढील टॅबवर जा. येथे आम्हाला संभाव्य पत्त्यांच्या यादीसह स्वागत आहे. तपासण्यासाठी तुम्ही एक किंवा अधिक पृष्ठे निवडू शकता:

आपल्याला इतर प्रोग्राम वापरण्याची आवश्यकता नाही या वस्तुस्थितीत सोय आहे.
दुर्दैवाने, असे बरेच निष्काळजी प्रोग्रामर नाहीत जे स्पष्ट मजकूरात संकेतशब्द संग्रहित करतात. बऱ्याचदा पासवर्ड लाइनमध्ये आपण असे काहीतरी पाहतो
8743b52063cd84097a65d1633f5c74f5
हे एक हॅश आहे. ब्रूट फोर्स वापरून तुम्ही ते डिक्रिप्ट करू शकता. आणि... jSQL इंजेक्शनमध्ये अंगभूत ब्रूट फोर्स आहे.
निःसंशय सुविधा अशी आहे की आपल्याला इतर प्रोग्राम्स शोधण्याची आवश्यकता नाही. बर्याच लोकप्रिय हॅशसाठी समर्थन आहे.
हा सर्वोत्तम पर्याय नाही. डिकोडिंग हॅशमध्ये गुरू होण्यासाठी, रशियन भाषेतील "" पुस्तकाची शिफारस केली जाते.
पण, अर्थातच, जेव्हा इतर कोणताही कार्यक्रम हातात नसतो किंवा अभ्यासासाठी वेळ नसतो, तेव्हा jSQL इंजेक्शन त्याच्या अंगभूत ब्रूट फोर्स फंक्शनसह खूप उपयुक्त ठरेल.
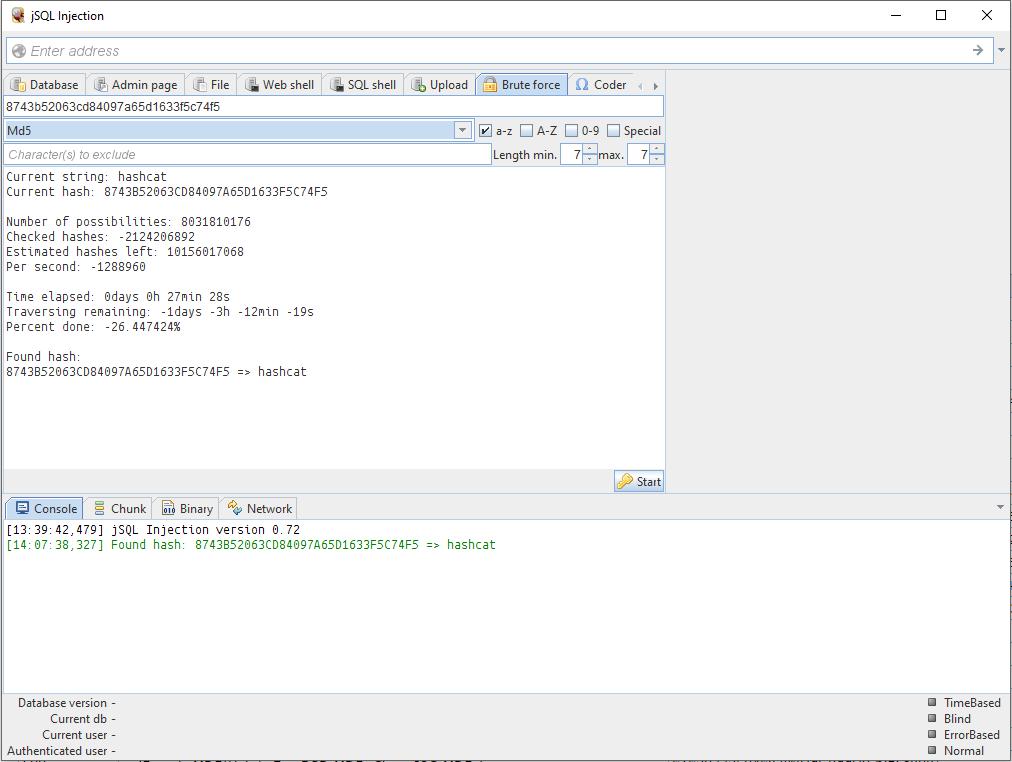
सेटिंग्ज आहेत: पासवर्डमध्ये कोणते वर्ण समाविष्ट केले जातील, पासवर्ड लांबी श्रेणी तुम्ही सेट करू शकता.
डेटाबेससह ऑपरेशन्स व्यतिरिक्त - ते वाचणे आणि सुधारणे, जर एसक्यूएल इंजेक्शन्स आढळल्यास, खालील फाइल ऑपरेशन्स केल्या जाऊ शकतात:
आणि हे सर्व jSQL इंजेक्शन मध्ये लागू केले आहे!
निर्बंध आहेत - SQL सर्व्हरकडे फाइल विशेषाधिकार असणे आवश्यक आहे. स्मार्ट सिस्टम प्रशासकांनी त्यांना अक्षम केले आहे आणि ते फाइल सिस्टममध्ये प्रवेश मिळवू शकणार नाहीत.
फाइल विशेषाधिकारांची उपस्थिती तपासणे अगदी सोपे आहे. एका टॅबवर जा (फायली वाचणे, शेल तयार करणे, नवीन फाइल अपलोड करणे) आणि निर्दिष्ट केलेल्या ऑपरेशन्सपैकी एक करण्याचा प्रयत्न करा.
आणखी एक अतिशय महत्त्वाची टीप - आपण ज्या फाईलसह कार्य करू त्याचा अचूक मार्ग आपल्याला माहित असणे आवश्यक आहे - अन्यथा काहीही कार्य करणार नाही.
खालील स्क्रीनशॉट पहा:
 फाईलवर ऑपरेट करण्याचा कोणताही प्रयत्न करण्यासाठी, आम्हाला खालील प्रतिसाद प्राप्त होतो: FILE विशेषाधिकार नाही(कोणतेही फाइल विशेषाधिकार नाहीत). आणि येथे काहीही केले जाऊ शकत नाही.
फाईलवर ऑपरेट करण्याचा कोणताही प्रयत्न करण्यासाठी, आम्हाला खालील प्रतिसाद प्राप्त होतो: FILE विशेषाधिकार नाही(कोणतेही फाइल विशेषाधिकार नाहीत). आणि येथे काहीही केले जाऊ शकत नाही.
त्याऐवजी तुम्हाला दुसरी त्रुटी असल्यास:
[directory_name] मध्ये लिहिण्यात समस्या
याचा अर्थ असा की तुम्ही फाइल लिहू इच्छित असलेला निरपेक्ष मार्ग चुकीचा निर्दिष्ट केला आहे.
निरपेक्ष मार्गाचा अंदाज लावण्यासाठी, तुम्हाला किमान सर्व्हर चालत असलेली ऑपरेटिंग सिस्टम माहित असणे आवश्यक आहे. हे करण्यासाठी, नेटवर्क टॅबवर स्विच करा.
असा रेकॉर्ड (ओळ Win64) आम्ही Windows OS शी व्यवहार करत आहोत असे मानण्याचे कारण देतो:
Keep-Alive: timeout=5, max=99 सर्व्हर: Apache/2.4.17 (Win64) PHP/7.0.0RC6 कनेक्शन: Keep-Alive पद्धत: HTTP/1.1 200 OK सामग्री-लांबी: 353 तारीख: शुक्र, 11 डिसेंबर 2015 11:48:31 GMT X-द्वारे समर्थित: PHP/7.0.0RC6 सामग्री-प्रकार: मजकूर/html; charset=UTF-8
येथे आमच्याकडे काही युनिक्स (*BSD, Linux):
हस्तांतरण-एनकोडिंग: खंडित तारीख: शुक्र, 11 डिसेंबर 2015 11:57:02 GMT पद्धत: HTTP/1.1 200 OK Keep-Alive: timeout=3, max=100 कनेक्शन: Keep-alive सामग्री-प्रकार: मजकूर/html X- द्वारा समर्थित: PHP/5.3.29 सर्व्हर: Apache/2.2.31 (Unix)
आणि येथे आमच्याकडे CentOS आहे:
पद्धत: HTTP/1.1 200 ओके कालबाह्य होईल: गुरु, 19 नोव्हेंबर 1981 08:52:00 GMT सेट-कुकी: PHPSESSID=9p60gtunrv7g41iurr814h9rd0; path=/ कनेक्शन: Keep-alive X-Cache-Lookup: MISS from t1.hoster.ru:6666 सर्व्हर: Apache/2.2.15 (CentOS) X-Powered by: PHP/5.4.37 X-Cache: MISS from t1.hoster.ru कॅशे-कंट्रोल: नो-स्टोअर, नो-कॅशे, मस्ट-रिव्हॅलिडेट, पोस्ट-चेक=0, प्री-चेक=0 प्राग्मा: नो-कॅशे तारीख: शुक्र, 11 डिसेंबर 2015 12:08:54 GMT हस्तांतरण-एनकोडिंग: खंडित सामग्री-प्रकार: मजकूर/html; charset=WINDOWS-1251
विंडोजवर, साइटसाठी एक सामान्य फोल्डर आहे C:\सर्व्हर\data\htdocs\. परंतु, खरं तर, जर एखाद्याने विंडोजवर सर्व्हर बनवण्याचा "विचार" केला असेल, तर बहुधा, या व्यक्तीने विशेषाधिकारांबद्दल काहीही ऐकले नाही. म्हणून, तुम्ही थेट C:/Windows/ डिरेक्ट्रीमधून प्रयत्न करायला सुरुवात केली पाहिजे:
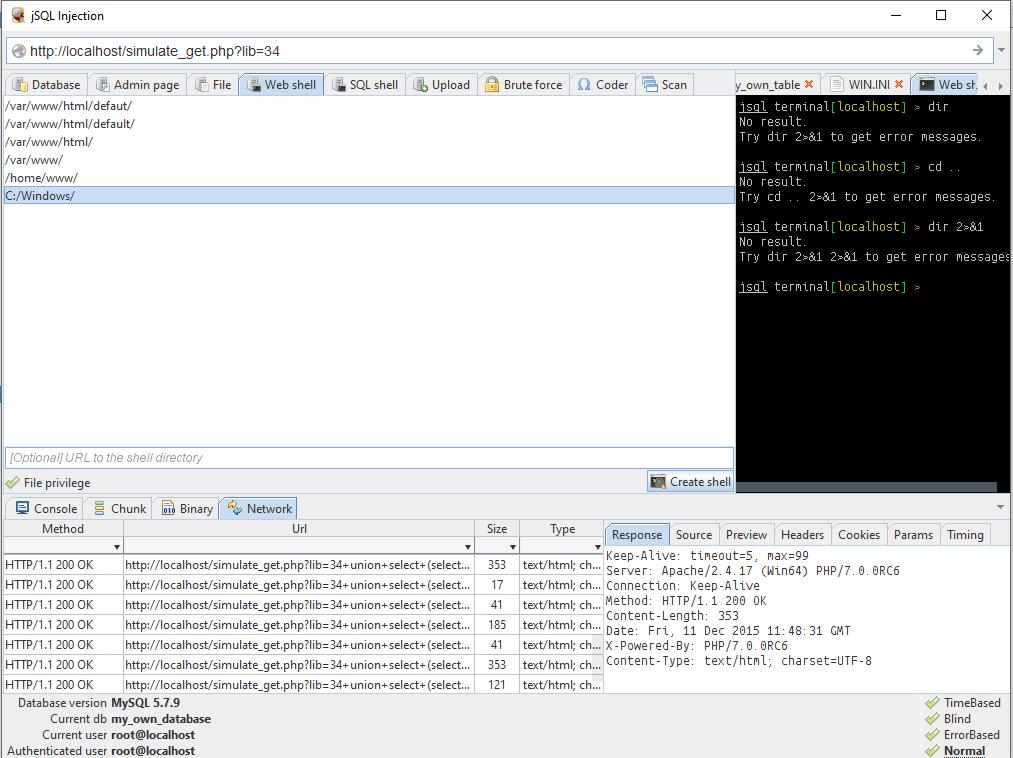
जसे आपण पाहू शकता, सर्वकाही प्रथमच ठीक झाले.
पण jSQL इंजेक्शन शेल्स स्वतःच माझ्या मनात शंका निर्माण करतात. तुमच्याकडे फाइल विशेषाधिकार असल्यास, तुम्ही वेब इंटरफेससह सहजपणे काहीतरी अपलोड करू शकता.
आणि हे कार्य jSQL Injection मध्ये देखील उपलब्ध आहे. सर्व काही अत्यंत सोपे आहे - साइट्सची सूची डाउनलोड करा (फाइलमधून आयात केली जाऊ शकते), तुम्हाला ज्यांना तपासायचे आहे ते निवडा आणि ऑपरेशन सुरू करण्यासाठी योग्य बटण क्लिक करा.
jSQL इंजेक्शन हे वेबसाइट्सवर आढळणारे SQL इंजेक्शन शोधण्यासाठी आणि नंतर वापरण्यासाठी एक चांगले, शक्तिशाली साधन आहे. त्याचे निःसंशय फायदे: वापरणी सोपी, अंगभूत संबंधित कार्ये. वेबसाइट्सचे विश्लेषण करताना jSQL Injection हा नवशिक्याचा सर्वात चांगला मित्र असू शकतो.
कमतरतांपैकी, मी डेटाबेस संपादित करण्याची अशक्यता लक्षात घेईन (किमान मला ही कार्यक्षमता सापडली नाही). सर्व GUI साधनांप्रमाणे, या प्रोग्रामचा एक तोटा स्क्रिप्टमध्ये वापरल्या जाण्याच्या अक्षमतेला कारणीभूत ठरू शकतो. तरीसुद्धा, या प्रोग्राममध्ये काही ऑटोमेशन देखील शक्य आहे - वस्तुमान साइट स्कॅनिंगच्या अंगभूत कार्याबद्दल धन्यवाद.
jSQL इंजेक्शन प्रोग्राम sqlmap पेक्षा वापरण्यास अधिक सोयीस्कर आहे. परंतु sqlmap अधिक प्रकारच्या SQL इंजेक्शन्सना समर्थन देते, फाइल फायरवॉल आणि काही इतर फंक्शन्ससह कार्य करण्यासाठी पर्याय आहेत.
तळ ओळ: jSQL इंजेक्शन हा नवशिक्या हॅकरचा सर्वात चांगला मित्र आहे.
काली लिनक्स एनसायक्लोपीडियामध्ये या प्रोग्रामसाठी मदत या पृष्ठावर आढळू शकते: http://kali.tools/?p=706
हा लेख बऱ्याच काळापूर्वी पुन्हा लिहायला हवा होता (खूप “सामन्यांवर बचत”), परंतु मी कधीच त्याकडे जाऊ शकलो नाही. आपण आपल्या तारुण्यात किती मूर्ख आहोत याची आठवण करून द्या.
कोणत्याही इंटरनेट संसाधनाच्या यशासाठी मुख्य निकषांपैकी एक म्हणजे त्याच्या ऑपरेशनची गती आणि दरवर्षी वापरकर्ते या निकषाच्या दृष्टीने अधिकाधिक मागणी करत आहेत. PHP स्क्रिप्ट्सचे ऑपरेशन ऑप्टिमाइझ करणे ही सिस्टम गती सुनिश्चित करण्याच्या पद्धतींपैकी एक आहे.
या लेखात, मी स्क्रिप्ट ऑप्टिमायझेशनवरील टिपा आणि तथ्यांचा माझा संग्रह लोकांसमोर मांडू इच्छितो. संग्रह संकलित करण्यासाठी मला बराच वेळ लागला आणि तो अनेक स्त्रोत आणि वैयक्तिक प्रयोगांवर आधारित आहे.
कठोर नियमांऐवजी टिपा आणि तथ्यांचा संग्रह का? कारण, मी पाहिल्याप्रमाणे, "पूर्णपणे योग्य ऑप्टिमायझेशन" नाही. अनेक तंत्रे आणि नियम परस्परविरोधी आहेत आणि त्या सर्वांचे पालन करणे अशक्य आहे. सुरक्षितता आणि सुविधेशी तडजोड न करता वापरण्यास स्वीकारार्ह असलेल्या पद्धतींचा संच तुम्हाला निवडावा लागेल. मी शिफारसीय स्थान घेतले आहे आणि म्हणून माझ्याकडे सल्ला आणि तथ्ये आहेत ज्यांचे तुम्ही अनुसरण करू शकता किंवा करू शकत नाही.
गोंधळ टाळण्यासाठी, मी सर्व टिपा आणि तथ्ये 3 गटांमध्ये विभागली:
हा लेख लिहिण्यासाठी अंशतः साहित्य वापरले होते.
मालवेअर हे अनाहूत किंवा धोकादायक प्रोग्राम आहेत जे...


हॅलो का सर्वात सामान्य कारणांपैकी एक...