Вредоносное ПО (malware) - это назойливые или опасные программы,...


Юникод
Материал из Википедии - свободной энциклопедии
Перейти к: навигация , поиск
Юнико́д (чаще всего) или Унико́д (англ. Unicode ) - стандарт кодирования символов , позволяющий представить знаки практически всех письменных языков .
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium , Unicode Inc . ). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы , математические символы, буквы греческого алфавита , латиницы и кириллицы , при этом становится ненужным переключение кодовых страниц .
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set ) и семейство кодировок (англ . UTF, Unicode transformation format ). Универсальный набор символов задаёт однозначное соответствие символов кодам - элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII с соответствующими кодами. Далее расположены области знаков различных письменностей, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде ).
1 Предпосылки создания и развитие Юникода 2 Версии Юникода 3 Кодовое пространство 4 Система кодирования 5 Модифицирующие символы 6 Формы нормализации 7 Двунаправленное письмо 8 Представленные символы 9 ISO/IEC 10646 10 Способы представления 11 Методы ввода 12 Проблемы Юникода 13 «Юникод» или «Уникод»? 14 См. также |
Предпосылки создания и развитие Юникода
К концу 1980-х годов стандартом стали 8-битные символы, при этом существовало множество разных 8-битных кодировок, и постоянно появлялись всё новые. Это объяснялось как постоянным расширением круга поддерживаемых языков, так и стремлением создать кодировку, частично совместимую с какой-нибудь другой (характерный пример - появление альтернативной кодировки для русского языка, обусловленное эксплуатацией западных программ, созданных для кодировки CP437 ). В результате появилось несколько проблем:
Проблема «кракозябр » (отображения документов в неправильной кодировке): её можно было решить либо последовательным внедрением методов указания используемой кодировки, либо внедрением единой для всех кодировки.
Проблема ограниченности набора символов: её можно было решить либо переключением шрифтов внутри документа, либо внедрением «широкой» кодировки. Переключение шрифтов издавна практиковалось в текстовых процессорах , причём часто использовались шрифты с нестандартной кодировкой , т. н. «dingbat fonts» - в итоге при попытке перенести документ в другую систему все нестандартные символы превращались в кракозябры.
Проблема преобразования одной кодировки в другую: её можно было решить либо составлением таблиц перекодировки для каждой пары кодировок, либо использованием промежуточного преобразования в третью кодировку, включающую все символы всех кодировок.
Проблема дублирования шрифтов: традиционно для каждой кодировки делался свой шрифт, даже если эти кодировки частично (или полностью) совпадали по набору символов: эту проблему можно было решить, делая «большие» шрифты, из которых потом выбираются нужные для данной кодировки символы - однако это требует создания единого реестра символов, чтобы определять, чему что соответствует.
Было признано необходимым создание единой «широкой» кодировки. Кодировки с переменной длиной символа, широко использующиеся в Восточной Азии, были признаны слишком сложными в использовании, поэтому было решено использовать символы фиксированной ширины. Использование 32-битных символов казалось слишком расточительным, поэтому было решено использовать 16-битные.
Таким образом, первая версия Юникода представляла собой кодировку с фиксированным размером символа в 16 бит, то есть общее число кодов было 2 16 (65 536). Отсюда происходит практика обозначения символов четырьмя шестнадцатеричными цифрами (например, U+04F0). При этом в Юникоде планировалось кодировать не все существующие символы, а только те, которые необходимы в повседневном обиходе. Редко используемые символы должны были размещаться в «области пользовательских символов» (private use area), которая первоначально занимала коды U+D800…U+F8FF. Чтобы использовать Юникод также и в качестве промежуточного звена при преобразовании разных кодировок друг в друга, в него включили все символы, представленные во всех наиболее известных кодировках.
В дальнейшем, однако, было принято решение кодировать все символы и в связи с этим значительно расширить кодовую область. Одновременно с этим, коды символов стали рассматриваться не как 16-битные значения, а как абстрактные числа, которые в компьютере могут представляться множеством разных способов (см. Способы представления ).
Поскольку в ряде компьютерных систем (например, Windows NT ) фиксированные 16-битные символы уже использовались в качестве кодировки по умолчанию, было решено все наиболее важные знаки кодировать только в пределах первых 65 536 позиций (так называемая англ. basic multilingual plane , BMP ). Остальное пространство используется для «дополнительных символов» (англ. supplementary characters ): систем письма вымерших языков или очень редко используемых китайских иероглифов, математических и музыкальных символов.
Для совместимости со старыми 16-битными системами была изобретена система UTF-16 , где первые 65 536 позиций, за исключением позиций из интервала U+D800…U+DFFF, отображаются непосредственно как 16-битные числа, а остальные представляются в виде «суррогатных пар» (первый элемент пары из области U+D800…U+DBFF, второй элемент пары из области U+DC00…U+DFFF). Для суррогатных пар была использована часть кодового пространства (2048 позиций), ранее отведённого для «символов для частного использования».
Поскольку в UTF-16 можно отобразить только 2 20 +2 16 −2048 (1 112 064) символов, то это число и было выбрано в качестве окончательной величины кодового пространства Юникода.
Хотя кодовая область Юникода была расширена за пределы 2 16 уже в версии 2.0, первые символы в «верхней» области были размещены только в версии 3.1.
Роль этой кодировки в веб-секторе постоянно растёт, на начало 2010 доля веб-сайтов, использующих Юникод, составила около 50 %.
Версии Юникода
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы, - а эта работа ведётся постоянно, поскольку изначально система Юникод включала только Plane 0 - двухбайтные коды, - выходят и новые документы ISO . Система Юникод существует в общей сложности в следующих версиях:
1.1 (соответствует стандарту ISO/IEC 10646-1:1993 ), стандарт 1991-1995 годов.
2.0, 2.1 (тот же стандарт ISO/IEC 10646-1:1993 плюс дополнения: «Amendments» с 1-го по 7-е и «Technical Corrigenda» 1 и 2), стандарт 1996 года.
3.0 (стандарт ISO/IEC 10646-1:2000), стандарт 2000 года.
3.1 (стандарты ISO/IEC 10646-1:2000 и ISO/IEC 10646-2:2001), стандарт 2001 года.
3.2, стандарт 2002 года .
4.0, стандарт 2003 .
4.01, стандарт 2004 .
4.1, стандарт 2005 .
5.0, стандарт 2006 .
5.1, стандарт 2008 .
5.2, стандарт 2009 .
6.0, стандарт 2010 .
6.1, стандарт 2012 .
6.2, стандарт 2012 .
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до 2 31 (2 147 483 648) кодовых позиций, было принято решение использовать лишь 1 112 064 для совместимости с UTF-16. Впрочем, даже и этого на текущий момент более чем достаточно - в версии 6.0 используется чуть менее 110 000 кодовых позиций (109 242 графических и 273 прочих символов).
Кодовое пространство разбито на 17 плоскостей по 2 16 (65536) символов. Нулевая плоскость называется базовой , в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая - для редко используемых иероглифов ККЯ , третья зарезервирована для архаичных китайских иероглифов . Плоскости 15 и 16 выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx » (для кодов 0…FFFF), или «U+xxxxx » (для кодов 10000…FFFFF), или «U+xxxxxx » (для кодов 100000…10FFFF), где xxx - шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код 044F 16 = 1103 10 .
Система кодирования
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы - это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
знаки пунктуации;
специальные знаки (математические , технические, идеограммы и пр.);
разделители.
Юникод - это система для линейного представления текста. Символы, имеющие дополнительные над- или подстрочные элементы, могут быть представлены в виде построенной по определённым правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character).
Модифицирующие символы
Представление символа «Й» (U+0419) в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306)
Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке . К ним относятся, в частности, знаки ударения и прочие диакритические знаки . Как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми (англ. base characters ), а непротяжённые - модифицирующими (англ. combining characters ); причём последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа « ́» (U+0301) или как монолитный символ «á» (U+00C1).
Особый тип модифицирующих символов - селекторы варианта начертания (англ. variation selectors ). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов монгольского квадратного письма .
Формы нормализации
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определённому стандартному виду.
В стандарте Юникода определены 4 формы нормализации текста:
Форма нормализации D (NFD) - каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных, в соответствии с таблицами декомпозиции.
Форма нормализации C (NFC) - каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция - текст обрабатывается от начала к концу и выполняются следующие правила:
Символ S является начальным , если он имеет нулевой класс модификации в базе символов Юникода.
В любой последовательности символов, стартующей с начального символа S, символ C блокируется от S, если и только если между S и C есть какой-либо символ B, который или является начальным, или имеет одинаковый или больший класс модификации, чем C. Это правило распространяется только на строки, прошедшие каноническую декомпозицию.
Первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода (или каноническая декомпозиция для хангыля и он не входит в список исключений ).
Символ
X может быть первично совмещён с символом
Y, если и только если существует первичный
композит Z, канонически эквивалентный
последовательности
Если очередной символ C не блокируется последним встреченным начальным базовым символом L и он может быть успешно первично совмещён с ним, то L заменяется на композит L-C, а C удаляется.
Форма нормализации KD (NFKD) - совместимая декомпозиция. При приведении в эту форму все составные символы заменяются, используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке.
Форма нормализации KC (NFKC) - совместимая декомпозиция с последующей канонической композицией.
Термины «композиция» и «декомпозиция» понимают под собой соответственно соединение или разложение символов на составные части.
Примеры
|
Исходный текст | ||||
|
\u0410, \u0401, \u0419 |
\u0410, \u0415\u0308, \u0418\u0306 |
\u0410, \u0401, \u0419 |
||
Двунаправленное письмо
Стандарт Юникод поддерживает письменности языков как с направлением написания слева направо (англ. left - to - right , LTR ), так и с написанием справа налево (англ. right - to - left , RTL ) - например, арабское и еврейское письмо. В обоих случаях символы хранятся в «естественном» порядке; их отображение с учётом нужного направления письма обеспечивается приложением.
Кроме того, Юникод поддерживает комбинированные тексты, сочетающие фрагменты с разным направлением письма. Данная возможность называется двунаправленность (англ. bidirectional text , BiDi ). Некоторые упрощённые обработчики текста (например, в сотовых телефонах) могут поддерживать Юникод, но не иметь поддержки двунаправленности. Все символы Юникода поделены на несколько категорий: пишущиеся слева направо, пишущиеся справа налево, и пишущиеся в любом направлении. Символы последней категории (в основном это знаки пунктуации ) при отображении принимают направление окружающего их текста.
Представленные символы
Основная статья: Символы, представленные в Юникоде

Схема базовой плоскости Unicode, см. описание
Юникод включает практически все современные письменности , в том числе:
арабскую ,
армянскую ,
бенгальскую ,
бирманскую ,
глаголицу ,
греческую ,
грузинскую ,
деванагари ,
еврейскую ,
кириллицу ,
китайскую (китайские иероглифы активно используются в японском языке , а также достаточно редко в корейском ),
коптскую ,
кхмерскую ,
латинскую ,
тамильскую ,
корейскую (хангыль) ,
чероки ,
эфиопскую ,
японскую (которая включает в себя кроме китайских иероглифов ещё и слоговую азбуку ),
и другие.
С академическими целями добавлены многие исторические письменности, в том числе: германские руны , древнетюркские руны , древнегреческая , египетские иероглифы , клинопись , письменность майя , этрусский алфавит .
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм .
Однако в Юникод принципиально не включаются логотипы компаний и продуктов, хотя они и встречаются в шрифтах (например, логотип Apple в кодировке MacRoman (0xF0) или логотип Windows в шрифте Wingdings (0xFF)). В юникодовских шрифтах логотипы должны размещаться только в области пользовательских символов.
ISO/IEC 10646
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO /IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество Консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO ) началось в 1991 году . В 1993 году ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним Консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия ISO/IEC 10646 будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS значит универсальный многооктетный (многобайтовый) кодированный набор символов (англ. universal multiple - octet coded character set ). UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Способы представления
Юникод имеет несколько форм представления (англ. Unicode transformation format, UTF ): UTF-8 , UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 года были предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042 ).
В Microsoft Windows NT и основанных на ней системах Windows 2000 и Windows XP в основном используется форма UTF-16LE. В UNIX -подобных операционных системах GNU/Linux , BSD и Mac OS X принята форма UTF-8 для файлов и UTF-32 или UTF-8 для обработки символов в оперативной памяти .
Punycode - другая форма кодирования последовательностей Unicode-символов в так называемые ACE-последовательности, которые состоят только из алфавитно-цифровых символов, как это разрешено в доменных именах.
Основная статья: UTF-8
UTF-8 - представление Юникода, обеспечивающее наилучшую совместимость со старыми системами, использовавшими 8-битные символы. Текст, состоящий только из символов с номером меньше 128, при записи в UTF-8 превращается в обычный текст ASCII . И наоборот, в тексте UTF-8 любой байт со значением меньше 128 изображает символ ASCII с тем же кодом. Остальные символы Юникода изображаются последовательностями длиной от 2 до 6 байт (на деле, только до 4 байт, поскольку в Юникоде нет символов с кодом больше 10FFFF, и вводить их в будущем не планируется), в которых первый байт всегда имеет вид 11xxxxxx, а остальные - 10xxxxxx.
Формат UTF-8 был изобретён 2 сентября 1992 года Кеном Томпсоном и Робом Пайком и реализован в Plan 9 . Сейчас стандарт UTF-8 официально закреплён в документах RFC 3629 и ISO/IEC 10646 Annex D.
Символы UTF-8 получаются из Unicode следующим образом :
0x00000000 - 0x0000007F: 0xxxxxxx
0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx
0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx
0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Теоретически возможны, но не включены в стандарт также:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы должны отвергаться по соображениям безопасности.
Порядок байтов
В потоке данных UTF-16 старший байт может записываться либо перед младшим (англ. UTF-16 little-endian ), либо после младшего (англ . UTF-16 big-endian ). Аналогично существует два варианта четырёхбайтной кодировки - UTF-32LE и UTF-32BE.
Для определения формата представления Юникода в начало текстового файла записывается сигнатура - символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый меткой порядка байтов (англ. byte order mark , BOM ). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует. Также этот способ иногда применяется для обозначения формата UTF-8, хотя к этому формату и неприменимо понятие порядка байтов. Файлы, следующие этому соглашению, начинаются с таких последовательностей байтов:
К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом (хотя реальные тексты редко начинаются с него).
Файлы в кодировках UTF-16 и UTF-32, не содержащие BOM, должны иметь порядок байтов big-endian (unicode.org ).
Юникод и традиционные кодировки
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше кодировка задавалась шрифтом, то теперь она задаётся таблицей соответствия между данной кодировкой и Юникодом. Фактически 8-битные кодировки превратились в форму представления некоторого подмножества Юникода. Это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки в Юникод.
Кроме того, многие форматы данных позволяют вставлять любые символы Юникода, даже если документ записан в старой 8-битной кодировке. Например, в HTML можно использовать коды с амперсандом .
Реализации
Большинство современных операционных систем в той или иной степени обеспечивают поддержку Юникода.
В операционных системах семейства Windows NT для внутреннего представления имён файлов и других системных строк используется двухбайтовая кодировка UTF-16LE. Системные вызовы, принимающие строковые параметры, существуют в однобайтном и двухбайтном вариантах. Подробнее см. в статье .
UNIX -подобные операционные системы, в том числе GNU/Linux , BSD , Mac OS X , используют для представления Юникода кодировку UTF-8. Большинство программ могут работать с UTF-8 как с традиционными однобайтными кодировками, не обращая внимания на то, что символ представляется как несколько последовательных байт. Для работы с отдельными символами строки обычно перекодируются в UCS-4, так что каждому символу соответствует машинное слово .
Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java . В ней принципиально отказались от 8-битного представления символов в пользу 16-битного. Это решение увеличивало расход памяти, но позволило вернуть в программирование важную абстракцию: произвольный одиночный символ (тип char). В частности, программист мог работать со строкой, как с простым массивом. К сожалению, успех не был окончательным, Юникод перерос ограничение в 16 бит и к версии J2SE 5.0 произвольный символ снова стал занимать переменное число единиц памяти - один char или два (см. суррогатная пара ).
Сейчас большинство языков программирования поддерживают строки Юникода, хотя их представление может различаться в зависимости от реализации.
Методы ввода
Поскольку ни одна раскладка клавиатуры не может позволить вводить все символы Юникода одновременно, от операционных систем и прикладных программ требуется поддержка альтернативных методов ввода произвольных символов Юникода.
Microsoft Windows
Основная статья: Юникод в операционных системах Microsoft
Начиная с Windows 2000 , служебная программа «Таблица символов» (charmap.exe) показывает все символы в ОС и позволяет копировать их в буфер обмена . Похожая таблица есть, например, в Microsoft Word .
Иногда можно набрать шестнадцатеричный код, нажать Alt +X, и код будет заменён на соответствующий символ, например, в WordPad , Microsoft Word. В редакторах Alt+X выполняет и обратное преобразование.
Во многих программах MS Windows, чтобы получить символ Unicode, нужно при нажатой клавише Alt набрать десятичное значение кода символа на цифровой клавиатуре. Например, полезными при наборе кириллических текстов будут комбинации Alt+0171 («) и Alt+0187 (»). Интересны также комбинации Alt+0133 (…) и Alt+0151 (-).
Macintosh
В Mac OS 8.5 и более поздних версиях поддерживается метод ввода, называемый «Unicode Hex Input». При зажатой клавише Option требуется набрать четырёхзначный шестнадцатеричный код требуемого символа. Этот метод позволяет вводить символы с кодами, большими U+FFFF, используя пары суррогатов; такие пары операционной системой будут автоматически заменены на одиночные символы. Этот метод ввода перед использованием нужно активизировать в соответствующем разделе системных настроек и затем выбрать как текущий метод ввода в меню клавиатуры.
Начиная с Mac OS X 10.2, существует также приложение «Character Palette», позволяющее выбирать символы из таблицы, в которой можно выделять символы определённого блока или символы, поддерживаемые конкретным шрифтом.
GNU/Linux
В GNOME также есть утилита «Таблица символов», позволяющая отображать символы определённого блока или системы письма и предоставляющая возможность поиска по названию или описанию символа. Когда код нужного символа известен, его можно ввести в соответствии со стандартом ISO 14755: при зажатых клавишах Ctrl + ⇧ Shift ввести шестнадцатеричный код (начиная с некоторой версии GTK+ ввод кода нужно предварить нажатием клавиши «U» ). Вводимый шестнадцатеричный код может иметь до 32 бит в длину, позволяя вводить любые символы Юникода без использования суррогатных пар.
IMS (IP Multimedia Subsystem) – спецификация передачи мультимедийного содержимого в сетях электросвязи на основе протокола IP. Ее авторство принадлежит международному партнерству 3-d Generation Partnership Project (3GPP), объединившему European Telecommunications Standardization Institute (ETSI) и несколько национальных организаций стандартизации. IMS изначально разрабатывалась применительно к построению мобильных сетей 3-го поколения на базе протокола IP. В дальнейшем концепция была принята комитетом ETSI-TISPAN, усилия которого были направлены на спецификацию протоколов и интерфейсов, необходимых для поддержки и реализации широкого спектра услуг в стационарных сетях с использованием стека протоколов IP.
В настоящее время архитектура IMS рассматривается многими операторами и сервис-провайдерами, а также поставщиками оборудования как возможное решение для построения сетей следующего поколения и как основа конвергенции мобильных и стационарных сетей на платформе IP.
Принцип, на котором строится концепция IMS, состоит в том, что доставка любой услуги никаким образом не соотносится с коммуникационной инфраструктурой (за исключением ограничений по пропускной способности). Воплощением этого принципа является многоуровневый подход, используемый при построении IMS. Он позволяет реализовать независимый от технологии доступа открытый механизм доставки услуг, который дает возможность задействовать в сети приложения сторонних поставщиков услуг.
В Табл. 1 приведен перечень всех интерфейсов подсистемы IMS (включая интерфейсы взаимодействия с сетью доступа LTE), а на Рис. 1 показана общая архитектура сети.
|
Наименование |
Объекты |
Протокол |
|
LTE user/control plane |
||
|
HSS – S-CSCF/I-CSCF |
||
|
SLF – S-CSCF/I-CSCF |
||
|
eMSS – S-CSCF/I-CSCF |
||
|
P-GW – IMS-AGW / MRFP / |
||
|
CSCF/BGCF – IBCF |
||
|
Interface to OCS |
||
|
Interface to CDF |
||
|
CGF – billing system |
||
Рис.1 (архитектура сети IMS):
Рассмотрим базовые элементы более подробно.
1. Call Session Control Function (CSCF) – функция управления сеансом связи
Существуют 4 различных типа CSCF – прокси CSCF (proxy CSCF – P-CSCF), обслуживающий CSCF (serving CSCF – S-CSCF), запрашивающий CSCF (interrogating CSCF – I-CSCF) и CSCF экстренных служб (emergency CSCF – E-CSCF).
Каждый CSCF выполняет свои специализированные задачи. Общая их роль заключается в участии в процессах регистрации абонентского терминала в сети, установления сессии и обеспечении механизм SIP маршрутизации.
Кроме того, все CSCF могут генерировать тарификационные данные и направлять их в функции offline тарификации.
a) Proxy Call Session Control Function (P-CSCF)
P-CSCF – является точкой входа пользователей в IMS. Весь сигнальный IMS трафик абонентский терминал (UE) направляет на P-CSCF. Аналогично весь сигнальный трафик, генерируемый сетью в направлении к UE – посылается через P-CSCF.
Существуют 5 уникальных задач, выполняемых P-CSCF:
SIP протокол является текстовым протоколом и включает большое кол-во заголовков, параметров, расширений и т.д. Учитывая текстовую основу протокола, размер SIP сообщений существенно превышает размер сообщений бинарных протоколов. Соответственно, для ускорения процедуры установления сессий необходима обязательная поддержка SIP компрессии между UE и P-CSCF. Режим компрессии включается P-CSCF в случае если UE индицирует необходимость этого.
Учитывая, что во многих сетях связи абонентские терминалы (UE) располагаются за NAT-ом, который модифицирует на сетевом уровне IP/port информацию всех пакетов, проходящих через него, возникает проблема, обусловленная тем, что классический тип NAT-ирования не принимает во внимание IP информацию на SIP и SDR уровнях. Действительно всеобъемлющий IMS доступ (возможность UE взаимодействовать с P-CSCF независимо от среды доступа) требует, чтобы IP информация в SIP/SDP и user plane соответствовала информации на сетевом (IP) уровне (из публичного пула IP адресации). Для модификации IP на уровне user plane P-CSCF управляет шлюзом сети доступа, который обеспечивает модификацию IP на уровне user plane.
Задача P-CSCF в этом случае – детектирование запроса экстренного вызова и выбор E-CSCF для обработки данного экстренного вызова.
b) Interrogating Call Session Control Function (I-CSCF)
I-CSCF является точкой в сети оператора для всех входящих соединений к абонентам данного оператора. Основная задача, выполняемая I-CSCF – назначение S-CSCF, основываясь на данных, полученных из HSS.
Назначение S-CSCF происходит при регистрации пользователя или в ситуации, когда незарегистрированный пользователь получает SIP request к сервису, относящемуся к незарегистрированному состоянию (например, voice mail).
c) Serving Call Session Control Function (S-CSCF)
S-CSCF является центральной точкой IMS. Он обеспечивает выполнение процедуры регистрации, принятие решение о маршрутизации, управление машиной состояний сессии, хранение профиля пользователя.
Когда пользователь посылает запрос на регистрацию, он в конечном итоге маршрутизируется к S-CSCF, который инициирует процедуру аутентификации и загружает профиль пользователя из HSS. Получив и верифицировав данные, S-CSCF подтверждает регистрацию, после чего пользователь может генерировать и принимать IMS запросы.
S-CSCF использует информацию, содержащуюся в пользовательском профиле, для принятия решения – когда и какую AS подключать при получении от пользователя SIP запроса. Кроме того, пользовательский профиль может содержать инструкции о типе медиа политик, которые S-CSCF должен применить. Например, он может индицировать, что пользователю доступны только аудио компоненты, при этом видео компоненты не доступны.
После получения S-CSCF запроса исходящей (UE-originated) или входящей (UE-terminated) сессии S-CSCF отвечает за принятие решений о его дальнейшей маршрутизации. Например, при получении запроса исходящей сессии (UE-originated) S-CSCF принимает решение – требуется ли ему подключать AS перед дельнейшей маршрутизацией запроса. После взаимодействия с AS S-CSCF либо продолжит сессию в IMS домене, либо переправит ее в другой домен (CS или IMS другого оператора). Если UE использует MSISDN для адресации вызываемой стороны, то S-CSCF преобразует MISISDN в SIP URI формат перед дальнейшей пересылкой, т.к. IMS не маршрутизирует запросы, основываясь на MSISDN номерах. Аналогично S-CSCF принимает все запросы, которые будут терминироваться в UE. Несмотря на то, что S-CSCF знает IP адрес UE (после процедуры регистрации) он маршрутизирует все запросы только через P-CSCF, т.к. P-CSCF может применять политики безопасности доступа.
Дополнительно S-CSCF может послать тарификационную информацию в OCS для обеспечения on-line тарификации.
d) Emergency Call Session Control Function (E-CSCF)
E-CSCF – это выделенная функциональность для обработки экстренных запросов – вызов полиции, пожарной бригады, скорой помощи.
Основная задача E-CSCF – выбрать соответствующий центр экстренных служб (public safety answering point – PSAP), в который должен быть перенаправлен поступивший запрос. Как правило, в качестве критерия выбора PSAP выступает местоположение пользователя и тип вызываемой службы.
2. Серверы приложений (Application Server – AS)
Строго говоря, серверы приложений (Application Server – AS) предоставляют услуги с добавленной стоимостью (value-added multimedia services) и не являются объектами IMS, т.к. располагаются в модели взаимодействия на вышележащем уровне. AS размещаются либо у оператора в домашней сети пользователя, либо у сервисного провайдера. Основные функции AS:
Предоставляемые услуги не ограничиваются только чистыми SIP сервисами. Оператор может предоставлять в т.ч. CAMEL (customized applications for mobile network enhanced logic) и OSA (open service architecture) сервисы для своих IMS абонентов в соответствии с 3GPP TS 23.228.
Таким образом, под AS будем понимать SIP AS, OSA service capability server (SCS) и CAMEL IP multimedia service switching function (IM-SSF).
С точки зрения S-CSCF элементы SIP AS, OSA SCS и IM-SSF представляют собой однотипные модули. Поскольку пользователь может иметь несколько сервисов, то может существовать и несколько AS в профиле каждого пользователя. В одну сессию может быть вовлечен один или несколько AS. Для примера, оператор может иметь одну AS для предоставления голосовых supplementary services (например, услуга переадресации всех входящих голосовых вызовов с 17:00 до 19:00 на голосовую почту) и другую AS для предоставления услуги voice call continuity (handover VoLTE в 2G/3G CS call).
3. Контролер и Процессор мультимедийных ресурсов (Media Resource Function Controller – MRFC, Media Resource Function Processor – MRFP)
MRFC и MRFP обеспечивают предоставление таких сервисов, как конференц-связь, проигрывание голосовых сообщений (анноунсемент), транскодирование медиа потоков. MRFC – обрабатывает SIP сигнализацию к/от S-CSCF/AS и управляет MRFP. MRFP - предоставляет user-plane ресурсы в соответствии с командами, полученными от MRFC:

Для направления вызова в домен с коммутацией каналов (CS домен) S-CSCF пересылает SIP запрос к BGCF, который осуществляет выбор соответствующего CS домена. При этом CS домен может быть выбран как на текущем узле (в соответствии с местонахождением пользователя, совершившего вызов), так и в другой сети. Если CS домен выбирается в другой сети – BGCF направляет запрос BGCF данной сети. Далее от BGCF запрос направляется в MGCF. Описанная опция позволяет маршрутизировать сигнальный и медиа поток по сети IMS максимально близко к вызываемому абоненту.
Когда SIP запрос достигает MGCF он выполняет преобразование протоколов (SIP протокол с одной стороны и ISDN user part – ISUP с другой) после чего – посылает конвертированный сообщение в SGW CS домена. SGW выполняет двухстороннее преобразование транспортного уровня сигнализации (SIGTRAN IP/SCTP/MxUA с одной стороны и SS7 MTP с другой стороны). SGW не обрабатывает уровень приложений (application level) сигнализации (ISUP). На Рис. 2 SGW является частью IM-MGW.
MGCF также осуществляет управление IM-MGW. IM-MGW обеспечивает user-plane линк между IMS и CS доменами. Он терминирует TDM каналы CS домена с одной стороны и медиа поток IMS домена с другой; выполняет их преобразование, транскодирование (при необходимости) и обработку пользовательской сигнализации.
В дополнение IM-MGW может генерировать тональные сигналы и анноунсементы пользователям в CS домене.
Сигнализация, относящаяся к входящим вызовам из CS домена (ISUP) в направлении к IMS пользователям направляется в MGCF, где выполняется ее преобразование в SIP запросы, которые далее направляются в I-CSCF для терминирования.

IP short message gateway (IP-SM-GW) соединяет наиболее распространенную технологию мобильного обмена сообщениями SMS с IMS мессажингом. Когда SMS посылается к IMS пользователю – SMS маршрутизируется по сети сигнализации SS7 к IP-SM-GW, который помещает полученную SMS в качестве контента специального типа в SIP MESSAGE и направляет его в S-CSCF для дальнейшей маршрутизации. Это позволяет доставлять SMS сообщения пользователям, которые зарегистрированы не в 3GPP мобильных IP сетях (Wi-Fi, WiMAX), а также может рассматриваться как альтернатива традиционным методам доставки SMS сообщений (CS, GPRS).
IP-SM-GW также позволяет доставлять SMS в обратном направлении (от абонентов IMS сетей пользователям CS 2G/3G сетей). Когда IMS абонент отправляет SIP сообщение, содержащее SMS как специальный тип контента (special content type), IP-SM-GW извлекает его и направляет в SMS центр (SMSC) для дальнейшей доставки по сетям SS7. Данный тип взаимодействия позволяет предоставлять все существующие SMS услуги (в т.ч. услуги с дополнительной оплатой) абонентам, зарегистрированным в IMS сетях. Эта функциональность называется SMS over IP (3GPP TS 23.204).
Дополнительно IP-SM-GW может поддерживать "родной" (native) сервис взаимодействия между SMS и SIP-based аппликациями. При этом SMS конвертируется в native SIP запрос и со стороны IMS UE не требуется поддержка SMS технологии.
Существует ограничивающий фактор, который нужно принимать во внимание, а именно – размер SIP сообщения (RFC3428) должен быть как минимум на 200 байт меньше MTU (maximum transmission unit). Если IP-SM-GW принимает сцепленное (concatenated) SMS сообщение (группа сообщений стандартной длины, вместе формирующих одно сообщение большой длины) и размер SIP MESSAGE превышает возможный лимит, IP-SM-GW должен использовать сессионный режим (session mode).
Сессионный режим предполагает изначальную установку сессии между IMS UE и IP-SM-GW, для чего IP-SM-GW посылает SIP INVITE. Как только сессия установлена MSRP протокол (message session relay protocol) используется для доставки сообщения IMS UE.
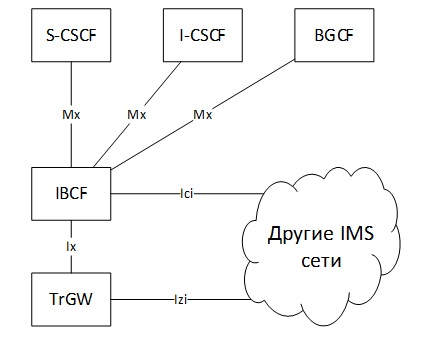
Функция взаимодействия между IMS сетями различных операторов связи реализуются посредством функционального модуля управления пограничным взаимодействием (Interconnection Border Control Function – IBCF) и транзитного шлюза (Transition Gateway – TrGW). Решаются следующие задачи:
7. Шлюз доступа IMS (IMS-AGW – Access Gateway)
В частных (например, домашних и офисных) фиксированных сетях абонентский терминал (UE) может находиться за NAT-ом и firewall-ом, установленных на сетевых устройствах, являющихся точками доступа в такие сети (customer premise equipment - CPE). При этом NAT не осуществляет модификацию / натирование информации на SIP / SDP уровнях.
Для решения данной задачи P-CSCF содержит функционал SIP ALG (application level gateway), который обеспечивает управление IMS-AGW. SIP INVITE запрос от UE с приватным IP адресом достигает P-CSCF, функционал ALG которого назначает публичный IP адрес, привязывает его к SIP сессии, выполняет NAT-ирование (замену приватных IP адресов на всех протокольных уровнях, включая IP, SIP, SDP), осуществляет его дальнейшую маршрутизацию и информирует шлюз доступа о созданной связке. При поступлении медиа потока между двумя абонентскими терминалами (UE) шлюз доступа будет осуществлять NAT-ирование RTP пакетов в/из публичного/частного адресного пространств.
8. Шлюз безопасности (Security Gateway – SEG)
Шлюз безопасности размещается на границе доменной зоны оператора и обеспечивает его защиту. Весь междоменный трафик должен в обязательном порядке проходить через SEG. SEG обеспечивает конфиденциальность, контроль целостности данных (data integrity) и аутентификацию в соответствии с 3GPP TS 33.203.
9. Функция извлечения информации о местоположении (Location Retrieval Function - LRF)
LRF ассистирует E-CSCF в обработке IMS экстренных вызовов путем предоставления информации о местоположении абонентского терминала (UE), инициировавшего экстренный вызов, которая используется для выбора экстренной службы (PSAP), куда сессия должна быть перенаправлена. Для получения информации о местонахождении пользователя LRF может иметь встроенный location server или иметь функционал GMLC (gateway mobile location center) – интерфейс к внешнему location server.
Для выбора соответствующего PSAP – LRF может содержать функцию RDF (routing determination function), которая используется для выбора адреса PSAP на основании информации о местоположении пользователя.
LRF может обеспечивать поддержку и других локальных регуляторных параметров, таких как emergency service routing number, location number, PSAP SIP URI, PSAP TEL URI,...
10. Расширенный мобильный центр коммутации – Enhanced MSC Server (eMSS)
eMSS представляет из себя MSC сетей 2G/3G, который обладает функциональностью P-CSCF в направлении IMS.
При регистрации пользователя в сети 2G/3G eMSS выполняет от имени пользователя регистрацию в IMS домене, что позволяет пользователю CS сети, не имеющему доступа в пакетную сеть, получить доступ к IMS услугам.
Когда пользователь совершает исходящий CS вызов (mobile originating call) eMSS конвертирует legacy CS вызов в запрос IMS сессии и направляет его на IMS систему. Аналогично, когда кто-либо совершает вызов к пользователю, обслуживаемому eMSS, входящий вызов (mobile terminating call) маршрутизируется на IMS платформу, выполняющую установленную процедуру управления входящим вызовом, включая HSS interrogation, и переправляющую SIP запрос на eMSS, который в свою очередь конвертирует протокол управления IMS сессией в протокол управления CS вызовом.
eMSS позволяет предоставлять услугу, действительно независимую от типа доступа (CS, IP-CAN, legacy), поскольку предоставление услуги всегда обеспечивается IMS платформой. Это обеспечивает возможность пользователям мигрировать из 2G/3G CS сетей в IMS и обратно.
11. Функция управления шлюзом доступа – Access Gateway Control Function (AGCF)
AGCF – представляет из себя точку входа для пользователей PSTN/ISDN сетей (аналоговые и ISDN телефоны). Он выполняет следующие функции:
С точки зрения IMS платформы AGCF выглядит как P-CSCF и обеспечивает соответствующий функционал (управление процедурой SIP регистрации и пр.).
Необходимая для тарификации информация собирается функциями тарификации различных модулей IMS из SIP запроса. При этом возможна online тарификация (в этом случае функция тарификации запрашивает разрешение у биллинговой системы на обработку SIP запроса) и offline тарификация (в этом случае функция тарификации всегда позволяет обработку SIP запроса, отправляя собранную тарификационную информацию в биллинговую систему для формирования CDR записей).
В зависимости от конфигурации IMS возможны различные схемы тарификации различных сервисов. При этом управление логикой тарификации осуществляется на основе срабатывания тех или иных триггеров. Триггерами могут быть:

Функции тарификации всех IMS модулей, а также модулей доступа могут взаимодействовать с offline модулем тарификации (offline charging entity – CDF), используя diameter-based Rf интерфейс (3GPP TS 32.299).
На основе информации, полученной из функциональных блоков тарификации всех IMS модулей, CDF создает CDR записи, которые переправляются в шлюз тарификации (charging gateway function – CGF) через Ga интерфейс (3GPP TS 32.295). Далее CGF обрабатывает полученные CDR и переправляет их в биллинговую систему используя Bх интерфейс (3GPP TS 32.240).
Prepaid сервисам необходима online тарификация. Это означает, что IMS сеть должна запрашивать OCS перед авторизацией пользователя на использование того или иного сервиса. OCS ответственен за контроль в реальном времени счета пользователя, авторизацию пользователя на использование сервиса и списание баланса со счета пользователя за полученные услуги. Только три IMS модуля (S-CSCF, AS, MRFC) взаимодействуют с OCS, используя интерфейс Ro. Кроме IMS модулей с OCS могут взаимодействовать не IMS модули. В частности, SGSN использует CAMEL application part (CAP). В дополнении к credit control (тарификация в on-line) OCS может создавать CDR записи подобно CGF.
HSS является хранилищем абонентских данных и данных, связанных с услугами. Он содержит функциональность центра аутентификации (AUC), LTE функциональность (SAE-HSS), GSM/UMTS функциональность (HLR), IMS функциональность (IMS-HSS), функциональность репозитория данных для управления тарификацией и политиками качества (SPR). Также HSS может использоваться для хранения данных серверов приложений (AS).

PCRF отвечает за формирование политик качества и управление тарификацией, основываясь на сессионной информации, полученной из P-CSCF.
Установление сессии в IMS обеспечивается обменом сигнальными сообщениями, используя SIP и SDP, включая согласование медиа характеристик (кодеков, IP адресов, номеров портов). Если оператор использует на своей сети PCRF, P-CSCF переправляет ему необходимую SDP информацию, на основании которой он создает политики и правила тарификации, а также авторизует IP потоки соответствующих медиа компонентов, мапируя данные SDP на IP QoS параметры для шлюза сети доступа, например, P-GW/PCEF.
Основываясь на доступной информации, PCRF применяет сформированные PCC политики и правила тарификации на шлюзе сети доступа (P-GW/PCEF), создает и модифицирует виртуальные соединения для переноса медиа-трафика (EPS bearer). В дополнение, PCRF принимает события с транспортного уровня, например, при потере радио-соединения, информируя об этих событиях P-CSCF, который в использует полученную информацию при формировании тарификационных данных и закрытии IMS сессии от имени пользователя.
Кроме того, PCRF может использоваться для обмена тарификационными идентификаторами, которые позволяют оператору коррелировать CDR, сгенерированные сетью доступа и сетью IMS; доставлять в сеть доступа метод тарификации (длительность, объем, оба); информацию rating group; команды активации on-line / off-line тарификации; адреса on-line / off-line систем тарификации; требуемый уровень отчетности, базирующийся на сервисе и rating-group.

В настоящее время в Беларуси оператор электросвязи Белтелеком усиленно внедряет телефонную связь на базе сети IMS. Предоставляется оборудование в пользование. Представляет оно собой обычный ADSL модем, но со встроенным SIP клиентом.
Но у нас есть CISCO 2951 с поднятой телефонией. Возникла мысль, а можно ли настроить такой телефонный номер без оборудования Белтелеком и напрямую в маршрутизаторе.
При разборе настроек в модеме выяснилось следующее. VoIP подается по отдельному PVC (VCI/VPI=2/35) в режиме IP/DHCP:

Модем получает настройки IP и шлюза по DHCP.

Нам важно запомнить адрес шлюза, для дальнейшей настройки на CISCO.
При заключении договора выдаются следующие данные:
Номер телефона: +37517xxxxxxx
Login: [email protected]
Необходимо также узнать пароль к сервису IMS: passIMS . У меня в маршрутизаторе Cisco установлена ADSL2 and ADSL2 High-Speed WAN Interface Cards .
Настраиваем сначала подключение по нужному PVC(2/35).
Interface ATM0/1/0.2 point-to-point
ip address dhcp
no ip proxy-arp
ip nat outside
ip virtual-reassembly in
atm route-bridged ip
pvc 2/35
encapsulation aal5snap
.02
в имени интерфейса выбрана произвольно, так как у меня уже есть одно соединение на этом же интерфейсе.
Sh int atm 0/1/0.2
убеждаемся что интерфейс поднялся и IP адрес получен.
Настройки SIP серверов тоже можно увидеть в модеме, если предварительно в telnet дать следующую команду: sendcmd 3 webd setconfig voippagedisp y .

Будем использовать один из SIP серверов, а именно 10.56.0.9 . Далее необходимо прописать маршруты.
Ip route 10.56.0.9 255.255.255.255 10.233.64.1
ip route 10.56.0.10 255.255.255.255 10.233.64.1
ip route 10.56.0.11 255.255.255.255 10.233.64.1
10.56.0.10
и 10.56.0.11
- это адрес RTP сервера обслуживающего аудио поток. Так как ims.beltel.by не имеет в DNS записи, то прописываем ее руками.
Ip host ims.beltel.by 10.56.0.9
Теперь переходим к непосредственной настройки sip-ua. Здесь есть особенность, авторизация должна проходить с указанием домена, т.е. вида [email protected]. Поэтому используем еще параметр number
.
Sip-ua
credentials number +37517xxxxxxx username [email protected] password PassIMS realm ims.beltel.by
authentication username +37517xxxxxxx password PassIMS realm ims.beltel.by
retry invite 3
retry response 3
retry bye 3
retry cancel 3
retry register 5
registrar dns:ims.beltel.by:5060 expires 3600 auth-realm ims.beltel.by
sip-server dns:ims.beltel.by:5060
connection-reuse
host-registrar
Об успешной регистрации будет видно из команды:
Dial-peer voice 8017 voip
description #toIMS#
translation-profile outgoing fromIMS
destination-pattern 8017.T
session protocol sipv2
session target sip-server
session transport udp
voice-class codec 1
dtmf-relay rtp-nte
no vad
Необходимо также обязательно подменять свой внутренний номер на номер выданный Белтелекомом, чтобы звонок обслуживался. Это делается через translation-profile
.
Voice translation-rule 1
rule 1 /.*/ /+37517xxxxxxx/
voice translation-profile fromIMS
translate calling 1
Так как у меня используются телефоны Cisco 6921, то для входящего звонка просто прописан параметр secondary
на внутреннем номере.
Ephone-dn 1 dual-line
number 1234 secondary +37517xxxxxxx no-reg both
Таким образом мы получаем SIPовский номер в нашу телефонную сеть без дополнительного стороннего оборудования и в цифровом виде.
Update: С недавнего времени Белтелеком начал работать по UDP протоколу. Поэтому для входящих соединений уже не получится вписать secondary номер. Необходимо делать dial-peer с входящим правилом.
Примерно такой:
Dial-peer voice 9192 voip
description #Incoming_IMS#
translation-profile incoming incomIMS
session protocol sipv2
session target dns:ims.beltel.by
session transport udp
incoming called-number +37517xxxxxxx
voice-class codec 1
dtmf-relay rtp-nte
где translation-profile incoming incomIMS
это правило сопоставления номера IMS вашему внутреннему, на который необходимо принять звонок.
Например:
Voice translation-rule 5 rule 1 /.*/ /1234/ voice translation-profile incomIMS translate called 5
Вредоносное ПО (malware) - это назойливые или опасные программы,...

Лучшие программы для восстановления данных с любых носителей информации....

Здравствуйте.Одна из самых распространенных причин, по которым тормозит...