Вредоносное ПО (malware) - это назойливые или опасные программы,...


Keras — популярная библиотека глубокого обучения, которая внесла большой вклад в коммерциализацию глубокого обучения. Библиотека Keras проста в использовании и позволяет создавать нейронные сети с помощью лишь нескольких строк кода Python.
Из статьи вы узнаете, как с помощью Keras создать нейронную сеть, предсказывающую оценку продукта пользователями по их отзывам, классифицируя ее по двум категориям: положительная или отрицательная. Эта задача называется анализом настроений (сентимент-анализ) , и мы решим ее с помощью сайта с кинорецензиями IMDb. Модель, которую мы построим, также может быть применена для решения других задач после незначительной модификации.
Обратите внимание, что мы не будем вдаваться в подробности Keras и глубокого обучения. Этот пост предназначен для того, чтобы предоставить схему в Keras и познакомить с ее реализацией.
Keras — это библиотека для Python с открытым исходным кодом, которая позволяет легко создавать нейронные сети. Библиотека совместима с , Microsoft Cognitive Toolkit, Theano и MXNet. Tensorflow и Theano являются наиболее часто используемыми численными платформами на Python для разработки алгоритмов глубокого обучения, но они довольно сложны в использовании.
Оценка популярности фреймворков машинного обучения по 7 категориям Keras, наоборот, предоставляет простой и удобный способ создания моделей глубокого обучения. Ее создатель, François Chollet, разработал ее для того, чтобы максимально ускорить и упростить процесс создания нейронных сетей. Он сосредоточил свое внимание на расширяемости, модульности, минимализме и поддержке Python. Keras можно использовать с GPU и CPU; она поддерживает как Python 2, так и Python 3. Keras компании Google внесла большой вклад в коммерциализацию глубокого обучения и , поскольку она содержит cовременные алгоритмы глубокого обучения, которые ранее были не только недоступными, но и непригодными для использования.
С помощью анализа настроений можно определить отношение (например, настроение) человека к тексту, взаимодействию или событию. Поэтому сентимент-анализ относится к области обработки естественного языка, в которой смысл текста должен быть расшифрован для извлечения из него тональности и настроений.
 Пример шкалы анализа настроений
Пример шкалы анализа настроений Спектр настроений обычно подразделяется на положительные, отрицательные и нейтральные категории. С использованием анализа настроений можно, например, прогнозировать мнение клиентов и их отношение к продукту на основе написанных ими обзоров. Поэтому анализ настроений широко применяется к обзорам, опросам, текстам и многому другому.
 Рецензии на сайте IMDb
Рецензии на сайте IMDb Датасет IMDb состоит из 50 000 обзоров фильмов от пользователей, помеченных как положительные (1) и отрицательные (0).
Датасет был создан исследователями Стэнфордского университета и представлен в статье 2011 года, в котором достигнутая точность предсказаний была равна 88,89%. Датасет также использовался в рамках конкурса сообщества Keggle «Bag of Words Meets Bags of Popcorn» в 2011 году.
Начнем с импорта необходимых зависимостей для предварительной обработки данных и построения модели.
%matplotlib inline import matplotlib import matplotlib.pyplot as plt import numpy as np from keras.utils import to_categorical from keras import models from keras import layers
Загрузим датесет IMDb, который уже встроен в Keras. Поскольку мы не хотим иметь данные обучения и тестирования в пропорции 50/50, мы сразу же объединим эти данные после загрузки для последующего разделения в пропорции 80/20 :
From keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
Изучим наш датасет:
Print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data)))) Categories: Number of unique words: 9998 length = print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length))) Average Review length: 234.75892 Standard Deviation: 173.0
Можно видеть, что все данные относятся к двум категориям: 0 или 1, что представляет собой настроение обзора. Весь датасет содержит 9998 уникальных слов, средний размер обзора составляет 234 слова со стандартным отклонением 173.
Рассмотрим простой способ обучения:
Print("Label:", targets) Label: 1 print(data)
Здесь вы видите первый обзор из датасета, который помечен как положительный (1). Нижеследующий код производит обратное преобразование индексов в слова, чтобы мы могли их прочесть. В нем каждое неизвестное слово заменяется на «#». Это делается с помощью функции get_word_index () .
Index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join() print(decoded) # this film was just brilliant casting location scenery story direction everyone"s really suited the part they played and you could just imagine being there robert # is an amazing actor and now the same being director # father came from the same scottish island as myself so i loved the fact there was a real connection with this film the witty remarks throughout the film were great it was just brilliant so much that i bought the film as soon as it was released for # and would recommend it to everyone to watch and the fly fishing was amazing really cried at the end it was so sad and you know what they say if you cry at a film it must have been good and this definitely was also # to the two little boy"s that played the # of norman and paul they were just brilliant children are often left out of the # list i think because the stars that play them all grown up are such a big profile for the whole film but these children are amazing and should be praised for what they have done don"t you think the whole story was so lovely because it was true and was someone"s life after all that was shared with us all
Пришло время подготовить данные. Нужно векторизовать каждый обзор и заполнить его нулями, чтобы вектор содержал ровно 10 000 чисел. Это означает, что каждый обзор, который короче 10 000 слов, мы заполняем нулями. Это делается потому, что самый большой обзор имеет почти такой же размер, а каждый элемент входных данных нашей нейронной сети должен иметь одинаковый размер. Также нужно выполнить преобразование переменных в тип float .
Def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")
Разделим датасет на обучающий и тестировочный наборы. Обучающий набор будет состоять из 40 000 обзоров, тестировочный — из 10 000.
Test_x = data[:10000] test_y = targets[:10000] train_x = data train_y = targets
Теперь можно создать простую нейронную сеть. Начнем с определения типа модели, которую мы хотим создать. В Keras доступны два типа моделей: последовательные и с функциональным API .
Затем нужно добавить входные, скрытые и выходные слои. Для предотвращения переобучения будем использовать между ними исключение («dropout» ). Обратите внимание, что вы всегда должны использовать коэффициент исключения в диапазоне от 20% до 50%. На каждом слое используется функция «dense» для полного соединения слоев друг с другом. В скрытых слоях будем используем «relu» , потому это практически всегда приводит к удовлетворительным результатам. Не бойтесь экспериментировать с другими функциями активации. На выходном слое используем сигмоидную функцию, которая выполняет перенормировку значений в диапазоне от 0 до 1. Обратите внимание, что мы устанавливаем размер входных элементов датасета равным 10 000, потому что наши обзоры имеют размер до 10 000 целых чисел. Входной слой принимает элементы с размером 10 000, а выдает — с размером 50.
Наконец, пусть Keras выведет краткое описание модели, которую мы только что создали.
# Input - Layer model.add(layers.Dense(50, activation = "relu", input_shape=(10000,))) # Hidden - Layers model.add(layers.Dropout(0.3, noise_shape=None, seed=None)) model.add(layers.Dense(50, activation = "relu") model.add(layers.Dropout(0.2, noise_shape=None, seed=None)) model.add(layers.Dense(50, activation = "relu")) # Output- Layer model.add(layers.Dense(1, activation = "sigmoid"))model.summary() model.summary() _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_1 (Dense) (None, 50) 500050 _________________________________________________________________ dropout_1 (Dropout) (None, 50) 0 _________________________________________________________________ dense_2 (Dense) (None, 50) 2550 _________________________________________________________________ dropout_2 (Dropout) (None, 50) 0 _________________________________________________________________ dense_3 (Dense) (None, 50) 2550 _________________________________________________________________ dense_4 (Dense) (None, 1) 51 ================================================================= Total params: 505,201 Trainable params: 505,201 Non-trainable params: 0 _________________________________________________________________
Теперь нужно скомпилировать нашу модель, то есть, по существу, настроить ее для обучения. Будем использовать оптимизатор «adam» . Оптимизатор — это алгоритм, который изменяет веса и смещения во время обучения. В качестве функции потерь используем бинарную кросс-энтропию (так как мы работаем с бинарной классификацией), в качестве метрики оценки — точность.
Model.compile(optimizer = "adam", loss = "binary_crossentropy", metrics = ["accuracy"])
Теперь можно обучить нашу модель. Мы будем делать это с размером партии 500 и только двумя эпохами, поскольку я выяснил, что модель начинает переобучаться , если тренировать ее дольше. Размер партии определяет количество элементов, которые будут распространяться по сети, а эпоха — это один проход всех элементов датасета. Обычно больший размер партии приводит к более быстрому обучению, но не всегда — к быстрой сходимости. Меньший размер партии обучает медленнее, но может быстрее сходиться. Выбор того или иного варианта определенно зависит от типа решаемой задачи, и лучше попробовать каждый из них. Если вы новичок в этом вопросе, я бы посоветовал вам сначала использовать размер партии 32 , что является своего рода стандартом.
Results = model.fit(train_x, train_y, epochs= 2, batch_size = 500, validation_data = (test_x, test_y)) Train on 40000 samples, validate on 10000 samples Epoch 1/2 40000/40000 [==============================] - 5s 129us/step - loss: 0.4051 - acc: 0.8212 - val_loss: 0.2635 - val_acc: 0.8945 Epoch 2/2 40000/40000 [==============================] - 4s 90us/step - loss: 0.2122 - acc: 0.9190 - val_loss: 0.2598 - val_acc: 0.8950
Проведем оценку работы модели:
Print(np.mean(results.history["val_acc"])) 0.894750000536
Отлично! Наша простая модель уже побила рекорд точности в статье 2011 года , упомянутой в начале поста. Смело экспериментируйте с параметрами сети и количеством слоев.
Полный код модели приведен ниже:
Import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0) def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32") test_x = data[:10000] test_y = targets[:10000] train_x = data train_y = targets model = models.Sequential() # Input - Layer model.add(layers.Dense(50, activation = "relu", input_shape=(10000,))) # Hidden - Layers model.add(layers.Dropout(0.3, noise_shape=None, seed=None)) model.add(layers.Dense(50, activation = "relu")) model.add(layers.Dropout(0.2, noise_shape=None, seed=None)) model.add(layers.Dense(50, activation = "relu")) # Output- Layer model.add(layers.Dense(1, activation = "sigmoid")) model.summary() # compiling the model model.compile(optimizer = "adam", loss = "binary_crossentropy", metrics = ["accuracy"]) results = model.fit(train_x, train_y, epochs= 2, batch_size = 500, validation_data = (test_x, test_y)) print("Test-Accuracy:", np.mean(results.history["val_acc"]))
Вы узнали, что такое анализ настроений и почему Keras является одной из наиболее популярных библиотек глубокого обучения.
Мы создали простую нейронную сеть с шестью слоями, которая может вычислять настроение авторов кинорецензий с точностью 89%. Теперь вы можете использовать эту модель для анализа бинарных настроений в других источниках, но для этого вам придется сделать их размер равным 10 000 или изменить параметры входного слоя.
Эту модель (с небольшими изменениями) можно применить и для решения других задач машинного обучения.
В этой части предсавлены ссылки на статьи из рунета о том, что такое нейросети. Многие из статей написаны оригинальным живым языком и очень доходчивы. Однако здесь по большей части рассматриваются только самые азы, самые простые конструкции. Здесь же можно найти сылки на литературу по нейросетям. Учебники и книги, как им и положено, написаны академическим или приближающимся к нему языком и содержат малопонятные абстрактные примеры построения нейросетей, их обучения и пр. Следует иметь ввиду, что терминология в разных статьях "плавает", что видно по комментариям к статьям. Из-за этого на первых порах может возникнуть "каша в голове".
О том, какие библиотеки существуют для Питона можно кратенько прочитать . Отсюда же я буду брать тестовые примеры для того, чтобв убедиться, что требуемый пакет установлен корректно.
Центральным объектом TensorFlow является граф потока данных, представляющий вычисления. Вершины графа представляют операции (operation), а ребра – тензоры (tensor) (многомерные массивы, являющиеся основой TensorFlow). Граф потока данных в целом является полным описанием вычислений, которые реализуются в рамках сессии (session) и выполняются на устройствах (device) (CPU или GPU). Как и многие другие современные системы для научных вычислений и машинного обучения, TensorFlow имеет хорошо документированный API для Python, где тензоры представлены в виде знакомых массивов ndarray библиотеки NumPy. TensorFlow выполняет вычисления с помощью высоко оптимизированного C++, а также поддерживает нативный API для C и C++.
Установка tensorflow хорошо описана в статье по первой ссылке. Однако, сейчас уже вышла версия Python 3.6.1. Её использовать не получиться. По крайней сере на данный момент (03.06.2017). Требуется версия 3.5.3, которую можно скачать . Ниже приведу последовательность, которая сработала у меня (немного не как к статье с Хабра). Непонятно почему, но Python 64-бит сделан под процессор AMD соответственно и всё остальное под него. После установки Phyton не забываем установить полный доспуп для пользователей если Python устанавливался для всех.
pip install --upgrade pip
pip install -U pip setuptools
pip3 install --upgrade tensorflow
pip3 install --upgrade tensorflow-gpu
pip install matplotlib /*Загружает 8,9 Мб и ещё пару небольших файлов */
pip install jupyter
"Голый Python" может показаться малоинтересным. Поэтому далее инструкция по установке в среду Anaconda . Это альтернативная сборка. Python уже интегрирован в неё.
На сайте опять фигурирует новая версия под Python 3.6, которую пока новый Google-продукт не поддерживает. Поэтому я сразу взял из архива более раннюю версию, а именно Anaconda3-4.2.0 - она подходит. Не забываем установить флажек регистрации Python 3.5. Конкретно Перед установкой Anaconda термилал лучше закрыть иначе он так и будет работать с устаревшим PATH. Также не забываем изменять права доступа пользователей иначе ничего не получиться.
conda create -n tensorflow
activate tensorflow
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.1.0-cp35-cp35m-win_amd64.whl /*Загружается из Сети 19.4 Мб, потом 7,7 Мб и ещё 0,317 Мб*/
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/gpu/tensorflow_gpu-1.1.0-cp35-cp35m-win_amd64.whl /*Загружается 48,6 Мб */
Скрин экрана установки: в Anaconda всё проходит удачно.
Аналогично для второго файла.
Ну и в заключение: для того, чтобы всё это заработало, нужно установить пакет CUDA Toolkits от NVIDEA (в случае использования GPU). Текущая поддерживаемая версия 8.0. Ещё нужно будет скачать и распаковать в папку с CUDA библиотеку cuDNN v5.1, но не более новой версии! После всех этих манипуляций TensorFlow заработает.

Пакет Theano входит PyPI самого Python. Сам по себе он маленький - 3,1 Мб, но тянет за собой зависимости ещё на 15 Мб - scipy. Для установки последнего нужен ещё модуль lapack... В общем, установка пакета theano под Windows будет означать "танцы с бубном". Ниже я постараюсь показать последовательность действий для того, чтобы пакет все-таки заработал.
При использовании Anaconda "танцы с бубном" при установке не актуальны. Достаточно команды:
conda install theano
и процесс проходит автоматически. Кстати, загружаються и пакеты GCC.

Под Python 3.5.3 устанавливается и запускается только более ранняя версия 0.17.1 взять которую можно . Есть нормальный инсталятор. Тем не менее прямо так под Windows он работать не будет - нужна библиотека scipy.
Для того, чтобы обозначенные выше два пакета заработали (речь о "голом" Phyton), нужно сделать некоторые предварительные действия.
Для запуска Scikit-Learn и Theano, как уже стало понятно из вышеизложнного, потребуется "потанцевать с бубном". Первое, что нам выдает Yandex - это кладезь мудрости, правда англоязычный, ресурс stackoverflow.com , где мы находим ссылочку на отличный архив почти всех существующих для Python, пакетов, скомпиллированных под Windows - lfd.uci.edu
Здесь есть готовые к установке сборки интересующих в данный момент пакетов, скомпиллированные для разных версий Python. В нашем случае требуются версии файлов, сореджание в своем имени строку "-cp35-win_amd64" потому что именно такой пакет Python был использован для установки. На stakowerflow, если поискать, то можно найти и "инструкции " по установке конкретно наших пакетов.
pip install --upgrade --ignore-installed http://www.lfd.uci.edu/~gohlke/pythonlibs/vu0h7y4r/numpy-1.12.1+mkl-cp35-cp35m-win_amd64.whl
pip install --upgrade --ignore-insalled http://www.lfd.uci.edu/~gohlke/pythonlibs/vu0h7y4r/scipy-0.19.0-cp35-cp35m-win_amd64.whl
pip --upgrade --ignore-installed pandas
pip install --upgrade --ignore-installed matplotlib
Два последних пакета возникли в моей цепочке из-за чужих "танцев с бубном". В зависимостях устанавливаемых пакетов их я не заметил, но видимо какие-то их комноненты нужны для нормального прохождения процесса установки.
Эти две связанные низкоуровневые библиотеки, написанные на Фортране, нужны для установки пакета Theano. Scikit-Learn может работать и на тех, которые "в скрытом виде" уже установились в других пакетах (см. выше). Собственно если Theano установлено версии 0.17 из exe-файла, то тоже заработает. В Anaconda по крайней мере. Тем не менее эти библиотеки тоже можно найти в Сети. Например . Более свежие сборки . Для работы готового пакета предыдущей версии это подходит. Для сборки нового пакета потребуются новые версии.
Также следует отметить, что в совершенно свежей сборке Anaconda пакет Theano устанавливается намного проще - одной командой, но мне, честно говоря, на данном этапе (нулевом) освоения нейросетей больше приглянулся TensorFlow, а он пока с новыми версиями Python не дружит.
Джеймс Лой, Технологический университет штата Джорджия. Руководство для новичков, после которого вы сможете создать собственную нейронную сеть на Python.
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, . Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры .
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Большинство статей по нейронным сетям при их описании проводят параллели с мозгом. Мне проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат, не вникая в подробности.
Нейронные сети состоят из следующих компонентов:
На приведенной ниже диаграмме показана архитектура двухслойной нейронной сети (обратите внимание, что входной уровень обычно исключается при подсчете количества слоев в нейронной сети).
Создание класса Neural Network на Python выглядит просто:
Выход ŷ простой двухслойной нейронной сети:
В приведенном выше уравнении, веса W и смещения b являются единственными переменными, которые влияют на выход ŷ.
Естественно, правильные значения для весов и смещений определяют точность предсказаний. Процесс тонкой настройки весов и смещений из входных данных известен как .
Каждая итерация обучающего процесса состоит из следующих шагов
Последовательный график ниже иллюстрирует процесс:

Как мы видели на графике выше, прямое распространение - это просто несложное вычисление, а для базовой 2-слойной нейронной сети вывод нейронной сети дается формулой:
Давайте добавим функцию прямого распространения в наш код на Python-е, чтобы сделать это. Заметим, что для простоты, мы предположили, что смещения равны 0.
Однако нужен способ оценить «добротность» наших прогнозов, то есть насколько далеки наши прогнозы). Функция потери как раз позволяет нам сделать это.
Есть много доступных функций потерь, и характер нашей проблемы должен диктовать нам выбор функции потери. В этой работе мы будем использовать сумму квадратов ошибок в качестве функции потери.

Сумма квадратов ошибок - это среднее значение разницы между каждым прогнозируемым и фактическим значением.
Цель обучения - найти набор весов и смещений, который минимизирует функцию потери.
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения.
Чтобы узнать подходящую сумму для корректировки весов и смещений, нам нужно знать производную функции потери по отношению к весам и смещениям.
Напомним из анализа, что производная функции - это тангенс угла наклона функции.

Если у нас есть производная, то мы можем просто обновить веса и смещения, увеличив/уменьшив их (см. диаграмму выше). Это называется .
Однако мы не можем непосредственно вычислить производную функции потерь по отношению к весам и смещениям, так как уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно правило цепи для помощи в вычислении.
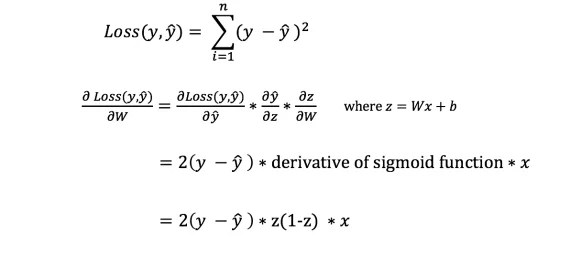
Фух! Это было громоздко, но позволило получить то, что нам нужно - производную (наклон) функции потерь по отношению к весам. Теперь мы можем соответствующим образом регулировать веса.
Добавим функцию backpropagation (обратного распространения) в наш код на Python-е:
Теперь, когда у нас есть наш полный код на Python-е для выполнения прямого и обратного распространения, давайте рассмотрим нашу нейронную сеть на примере и посмотрим, как это работает.
 Идеальный набор весов
Идеальный набор весов Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции.
Давайте тренируем нейронную сеть на 1500 итераций и посмотрим, что произойдет. Рассматривая график потерь на итерации ниже, мы можем ясно видеть, что потеря монотонно уменьшается до минимума. Это согласуется с алгоритмом спуска градиента, о котором мы говорили ранее.
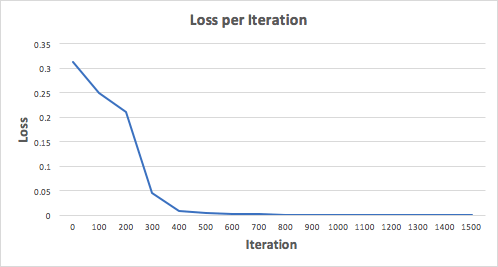
Посмотрим на окончательное предсказание (вывод) из нейронной сети после 1500 итераций.

Мы сделали это! Наш алгоритм прямого и обратного распространения показал успешную работу нейронной сети, а предсказания сходятся на истинных значениях.
Заметим, что есть небольшая разница между предсказаниями и фактическими значениями. Это желательно, поскольку предотвращает переобучение и позволяет нейронной сети лучше обобщать невидимые данные.
Я многому научился в процессе написания с нуля своей собственной нейронной сети. Хотя библиотеки глубинного обучения, такие как TensorFlow и Keras, допускают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я нахожу, что начинающим Data Scientist-ам полезно получить более глубокое их понимание.
Я инвестировал много своего личного времени в данную работу, и я надеюсь, что она будет полезной для вас!

Искусственные нейронные сети (ИНС) - математические модели, а также их программные или аппаратные реализации, построенные по принципу организации и функционирования биологических нейронных сетей - сетей нервных клеток живого организма.ИНС представляют собой систему соединённых и взаимодействующих между собой простых процессоров (искусственных нейронов).
Нейронные сети не программируются в привычном смысле этого слова, они обучаются. Возможность обучения - одно из главных преимуществ нейронных сетей перед традиционными алгоритмами. wikipedia
Нейронные сети были вдохновлены нашим собственным мозгом. Модель стандартного нейрона изобретена более пятидесяти лет назад и состоит из трех основных частей:
Работу нейрона можно описать примерно так: дендриды собирают сигналы, полученные от других нейронов, затем сомы выполняют суммирование и вычисление сигналов и данных, и наконец на основе результата обработки могут "сказать" аксонам передать сигнал дальше. Передача далее зависит от ряда факторов, но мы можем смоделировать это поведение как передаточную функцию, которая принимает входные данные, обрабатывает их и готовит выходные данные, если выполняются свойства передаточной функции.
Биологический нейрон - сложная система, математическая модель которого до сих пор полностью не построена. Введено множество моделей, различающихся вычислительной сложностью и сходством с реальным нейроном. Одна из важнейших - формальный нейрон (ФН). Несмотря на простоту ФН, сети, построенные из таких нейронов, могут сформировать произвольную много мерную функцию на выходе (источник: Заенцев И. В. Нейронные сети: основные модели).

Нейрон состоит из взвешенного сумматора и нелинейного элемента. Функционирование нейрона определяется формулами:
Нейрон имеет несколько входных сигналов x и один выходной сигнал OUT . Параметрами нейрона, определяющими его работу, являются: вектор весов w , пороговый уровень θ и вид функции активации F .
Нейронные сети привлекают к себе внимание за счет следующих возможностей:
К основным свойствам нейронных сетей можно отнести:
Способность обучаться . Нейронные сети не программируются, а обучаются на примерах. После предъявления входных сигналов (возможно, вместе с требуемыми выходами) сеть настраивают свои параметры таким образом, чтобы обеспечивать требуемую реакцию.
Обобщение . Отклик сети после обучения может быть до некоторой степени нечувствителен к небольшим изменениям входных сигналов. Эта внутренне присущая способность "видеть"" образ сквозь шум и искажения очень важна для распознавания образов. Важно отметить, что искусственная нейронная сеть делает обобщения автоматически благодаря своей структуре, а не с помощью использования "человеческого интеллекта"" в форме специально написанных компьютерных программ.
Параллелизм . Информация в сети обрабатывается параллельно, что позволяет достаточно выполнять сложную обработку данных с помощью большого числа простых устройств.
Высокая надежность . Сеть может правильно функционировать даже при выходе из строя части нейронов, за счет того, что вычисления производятся локально и параллельно.
Алгоритм решения задач с помощью многослойного персептрона (источник: Заенцев И. В. Нейронные сети: основные модели)
Чтобы построить многослойный персептрон, необходимо выбрать его параметры. Чаще всего выбор значений весов и порогов требует обучения, т.е. пошаговых изменений весовых коэффициентов и пороговых уровней.
Общий алгоритм решения:
Решаемые проблемы
Проблемы решаемые с помощью нейронных сетей ().
Классификация образов . Задача состоит в указании принадлежности входного образа (например, речевого сигнала или рукописного символа), представленного вектором признаков, одному или нескольким предварительно определенным классам. К известным приложениям относятся распознавание букв, распознавание речи, классификация сигнала электрокардиограммы, классификация клеток крови.
Кластеризация/категоризация . При решении задачи кластеризации, которая известна также как классификация образов "без учителя", отсутствует обучающая выборка с метками классов. Алгоритм кластеризации основан на подобии образов и размещает близкие образы в один кластер. Известны случаи применения кластеризации для извлечения знаний, сжатия данных и исследования свойств данных.
Аппроксимация функций . Предположим, что имеется обучающая выборка ((x1,y1), (x2,y2)..., (xn,yn)) (пары данных вход-выход), которая генерируется неизвестной функцией (x), искаженной шумом. Задача аппроксимации состоит в нахождении оценки неизвестной функции (x). Аппроксимация функций необходима при решении многочисленных инженерных и научных задач моделирования.
Предсказание/прогноз . Пусть заданы n дискретных отсчетов {y(t1), y(t2)..., y(tn)} в последовательные моменты времени t1, t2,..., tn . Задача состоит в предсказании значения y(tn+1) в некоторый будущий момент времени tn+1. Предсказание/прогноз имеют значительное влияние на принятие решений в бизнесе, науке и технике. Предсказание цен на фондовой бирже и прогноз погоды являются типичными приложениями техники предсказания/прогноза.
Оптимизация . Многочисленные проблемы в математике, статистике, технике, науке, медицине и экономике могут рассматриваться как проблемы оптимизации. Задачей алгоритма оптимизации является нахождение такого решения, которое удовлетворяет системе ограничений и максимизирует или минимизирует целевую функцию. Задача коммивояжера, относящаяся к классу NP-полных, является классическим примером задачи оптимизации.
Память, адресуемая по содержанию . В модели вычислений фон Неймана обращение к памяти доступно только посредством адреса, который не зависит от содержания памяти. Более того, если допущена ошибка в вычислении адреса, то может быть найдена совершенно иная информация. Ассоциативная память, или память, адресуемая по содержанию, доступна по указанию заданного содержания. Содержимое памяти может быть вызвано даже по частичному входу или искаженному содержанию. Ассоциативная память чрезвычайно желательна при создании мультимедийных информационных баз данных.
Управление . Рассмотрим динамическую систему, заданную совокупностью {u(t), y(t)}, где u(t) является входным управляющим воздействием, а y(t) - выходом системы в момент времени t. В системах управления с эталонной моделью целью управления является расчет такого входного воздействия u(t), при котором система следует по желаемой траектории, диктуемой эталонной моделью. Примером является оптимальное управление двигателем.
Виды архитектур
Архитектура нейронной сети - способ организации и связи отдельных элементов нейросети(нейронов). Архитектурные отличия самих нейронов заключаются главным образом в использовании различных активационных (возбуждающих) функций. По архитектуре связей нейронные сети можно разделить на два класса: сети прямого распространения и рекуррентные сети.
Классификация искусственных нейронных сетей по их архитектуре приведена на рисунке ниже.
Похожая классификация, но немного расширенная

Сеть прямого распространения сигнала (сеть прямой передачи) - нейронная сеть без обратных связей (петель). В такой сети обработка информации носит однонаправленный характер: сигнал передается от слоя к слою в направлении от входного слоя нейросети к выходному. Выходной сигнал (ответ сети) гарантирован через заранее известное число шагов (равное числу слоев). Сети прямого распространения просты в реализации, хорошо изучены. Для решения сложных задач требуют большого числа нейронов.
Сравнительная таблица многослойного персепторна и RBF-сети
| Многослойный персептрон | RBF-сети |
|---|---|
| Граница решения представляет собой пересечение гиперплоскостей | Граница решения - это пересечение гиперсфер, что задает границу более сложной формы |
| Сложная топология связей нейронов и слоев | Простая 2-слойная нейронная сеть |
| Сложный и медленно сходящийся алгоритм обучения | Быстрая процедура обучения: решение системы уравнений + кластеризация |
| Работа на небольшой обучающей выборке | Требуется значительное число обучающих данных для приемлемого результат |
| Универсальность применения: кластеризация, аппроксимация, управление и проч | Как правило, только аппроксимация функций и кластеризация |
Значение производной легко выражается через саму функцию. Быстрый расчет производной ускоряет обучение.
Гауссова кривая
Применяется в случаях, когда реакция нейрона должна быть максимальной для некоторого определенного значения NET.
Модули python для нейронных сетей
Простой пример
В качестве примера приведу простую нейроную сеть (простой персептрон ), которая после обучения сможет распознавать летающие объекты, не все, а только чайку :), все остальные входные образы будут распознаваться как НЛО .
# encoding=utf8 import random class NN: def __init__(self, threshold, size): """ Установим начальные параметры. """ self.threshold = threshold self.size = size self.init_weight() def init_weight(self): """ Инициализируем матрицу весов случайными данными. """ self.weights = [ for j in xrange(self.size)] def check(self, sample): """ Считаем выходной сигнал для образа sample. Если vsum > self.threshold то можно предположить, что в sample есть образ чайки. """ vsum = 0 for i in xrange(self.size): for j in xrange(self.size): vsum += self.weights[i][j] * sample[i][j] if vsum > self.threshold: return True else: return False def teach(self, sample): """ Обучение нейронной сети. """ for i in xrange(self.size): for j in xrange(self.size): self.weights[i][j] += sample[i][j] nn = NN(20, 6) # Обучаем нейронную сеть. tsample1 = [ , , , , , , ] nn.teach(tsample1) tsample2 = [ , , , , , , ] nn.teach(tsample2) tsample3 = [ , , , , , , ] nn.teach(tsample3) tsample4 = [ , , , , , , ] nn.teach(tsample4) # Проверим что может нейронная сеть. # Передадим образ чайки, который примерно похож на тот, про который знает персептрон. wsample1 = [ , , , , , , ] print u"чайка" if nn.check(wsample1) else u"НЛО" # Передадим неизвестный образ. wsample2 = [ , , , , , , ] print u"чайка" if nn.check(wsample2) else u"НЛО" # Передадим образ чайки, который примерно похож на тот, про который знает персептрон. wsample3 = [ , , , , , , ] print u"чайка" if nn.check(wsample3) else u"НЛО"
Вредоносное ПО (malware) - это назойливые или опасные программы,...

Лучшие программы для восстановления данных с любых носителей информации....

Здравствуйте.Одна из самых распространенных причин, по которым тормозит...