Вредоносное ПО (malware) - это назойливые или опасные программы,...
Заголовок статьи
Текст статьи, который кем-то написан. Инко Гнито - ее автор.
Семантика кода HTML всегда является горячим вопросом. Некоторые разработчики стараются всегда писать семантический код. Другие критикуют догматичных приверженцев. А некоторые даже понятия не имеют о том, что это такое и зачем оно нужно. Семантика определяется в HTML в тегах, классах, ID, и атрибутах, которые описывают назначение, но не задают точно содержание, которое в них заключено. То есть речь идет о разделении содержания и его формата.
Начнем с очевидного примера.
Текст статьи, который кем-то написан.
Инко Гнито - ее автор.Заголовок статьи
Вне зависимости от того, считаете ли вы, что HTML5 готов к использованию или нет, наверняка использование тега Но не все так четко представляется тегами HTML5. Давайте рассмотрим набор имен классов и разберемся с тем, отвечают ли они требованиям семантики. Не семантический код.
Это классический пример. Каждая рабочая среда CSS для модульной сетки использует такого типа имена классов для определения элементов сетки. Будет ли это "yui-b", "grid-4", или "spanHalf" - такие имена ближе к заданию разметки, чем к описанию содержания. Однако их использование в большинстве случаев неизбежно при работе с шаблонами модульных сеток. Семантический код.
Нижний колонтитул (footer
) приобрел устойчивое значение в веб дизайне. Это нижняя часть страницы, которая содержит такие элементы как повторяющаяся навигация, права использования, информацию об авторе и так далее. Данный класс определяет группу для всех этих элементов без их описания. Если вы перешли к использованию HTML5, то лучше применять элемент Не семантический код.
Он точно определяет содержание. Но почему текст должен быть большим? Чтобы выделяться среди другого более мелкого текста? "standOut
" (выделение) больше подходит в данном случае. Вы можете решить изменить стиль для выделяющего текста, но ничего не делать с его размером, и в таком случаем название класса может привести вас в замешательство. Семантический код.
В данном случае речь идет об определении уровня важности элемента в интерфейсе приложения (например, параграфа или кнопки). Элемент с более высоким уровнем может иметь яркие цвета и больший размер, а элементы с низким уровнем могут содержать больше содержания. Но точного определения стилей в данном случае нет, поэтому код является семантическим. Данная ситуация очень похожа на использование тегов Семантический код.
Если бы каждое имя класса можно было так четко определить! В данном случае мы имеем описание раздела, который имеет содержание, назначение которого легко описать, также как и "tweets", "pagination" или "admin-nav". Не семантический код.
В данном случае речь идет о задании стиля для первого параграфа на странице. Такой прием используется для привлечения внимания читателей к материалу. Лучше использовать имя "intro", в котором отсутствует упоминание элемента. Но еще лучше использовать селектор для таких параграфов, например article p:first-of-type или h1 + p . Не семантический код.
Это очень обобщенное имя класса, которое используется для организации форматирования элементов. Но в нем нет ничего, чтобы касалось описания содержания. Различные теоретики семантики рекомендуют в таких случаях использовать имя класса наподобие "group". Вполне вероятно, что они правы. Так как данный элемент, несомненно, служит для группирования нескольких других элементов, и рекомендуемое название будет лучше описывать его назначение без погружения в детали. Не семантический код.
Слишком детальное описание формата содержания. Лучше подобрать другое имя, которое будет описывать содержание, а не его формат. Семантический код.
Класс очень хорошо описывает статус содержания. Например, сообщение об успешном завершении операции может иметь совершенно другой стиль от сообщения об ошибке. Не семантический код.
В данном примере имеется попытка задать определение формата содержания, а не его назначения. "plain-jane" очень похоже на "normal" или "regular". Идеальный код CSS должен быть написан так, чтобы не возникало необходимости в именах класса наподобие "regular", которые описывают формат содержания. Не семантический код.
Такого типа классы обычно используются для определения элементов сайта, которые не должны включаться в цепочку ссылок. В данном случае лучше использовать что-то наподобие rel=nofollow для ссылок, но не класс для всего содержания. Не семантический код.
Здесь имеется попытка описать формат содержания, а не его назначение. Допустим, что у вас на сайте есть две статьи. И вы желаете задать им разные стили. "Обзоры фильмов" будут иметь голубой фон, а "Горячие новости" - красный фон и шрифт большего размера. Один из способов решить задачу такой: Другой способ такой: Наверняка, если опросить нескольких разработчиков о том, какой код более соответствует требованиям семантики, большинство укажет на первый вариант. Он отлично соответствует материалу данного урока: описание назначение без ссылок на форматирование. А второй вариант указывает на формат ("blueBg" - имя класса, которое сформировано из двух английских слов, означающих "голубой фон"). Если вдруг будет принято решение поменять дизайн обзоров фильмов - например, сделать зеленый фон, то имя класса "blueBg" превратится в кошмар разработчика. А имя "movie-review" позволит абсолютно спокойно изменять стили оформления с сохранением отличного уровня поддержки кода. Но никто не утверждает, что первый пример лучше во всех без исключения случаях. Допустим, что определённый оттенок синего используется во многих местах на сайте. Например, он является фоном для некоторой части нижнего колонтитула и областей в боковой панели. Вы можете воспользоваться следующим селектором: Movie-review,
footer > div:nth-of-type(2),
aside > div:nth-of-type(4) {
background: #c2fbff;
} Эффективное решение, так как цвет определяется только в одном месте. Но такой код становится сложным для поддержки, так как имеет длинный селектор, сложный для визуального восприятия. Также потребуются другие селекторы для определения уникальных стилей, что приведет к повторению кода. Или вы можете использовать другой подход и оставить их разделёнными: Movie-review {
background: #c2fbff;
/* Определение цвета */
}
footer > div:nth-of-type(2) {
background: #c2fbff;
/* И еще одно */
}
aside > div:nth-of-type(4) {
background: #c2fbff;
/* И еще одно */
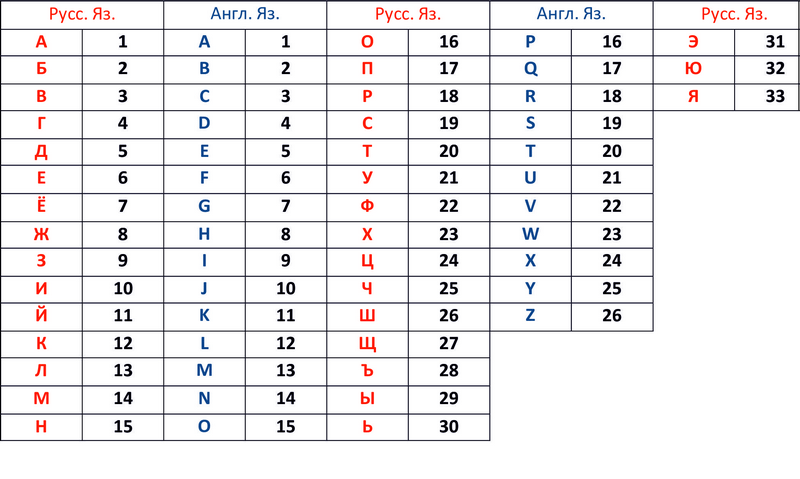
} Такой стиль помогает сохранять CSS файл более организованным (разные области определяются в разных разделах). Но платой является повторение определений. Для больших сайтов определение одного и того же цвета может доходить до нескольких тысяч раз. Ужасно! Вариантом решения может быть использование класса по типу "blueBg" для определения цвета один раз и вставки его в HTML коде, когда требуется использовать данный дизайн. Конечно, его лучше назвать "mainBrandColor" или "secondaryFont", чтобы отвязаться от описания форматирования. Можно пожертвовать семантикой кода в пользу сохранения ресурсов. Поскольку шифров в мире насчитывается огромное количество, то рассмотреть все шифры невозможно не только в рамках данной статьи, но и целого сайта. Поэтому рассмотрим наиболее примитивные системы шифрации, их применение, а так же алгоритмы расшифровки. Целью своей статьи я ставлю максимально доступно объяснить широкому кругу пользователей принципов шифровки \ дешифровки, а так же научить примитивным шифрам. Еще в школе я пользовался примитивным шифром, о котором мне поведали более старшие товарищи. Рассмотрим примитивный шифр «Шифр с заменой букв цифрами и обратно». Нарисуем таблицу, которая изображена на рисунке 1. Цифры располагаем по порядку, начиная с единицы, заканчивая нулем по горизонтали. Ниже под цифрами подставляем произвольные буквы или символы. Рис. 1 Ключ к шифру с заменой букв и обратно. Теперь обратимся к таблице 2, где алфавиту присвоена нумерация. Рис. 2 Таблица соответствия букв и цифр алфавитов. Теперь зашифруем словоК О С Т Е Р
: 1) 1. Переведем буквы в цифры:К = 12, О = 16, С =19, Т = 20, Ё = 7, Р = 18
2) 2. Переведем цифры в символы согласно таблицы 1. КП КТ КД ПЩ Ь КЛ
3) 3. Готово. Этот пример показывает примитивный шифр. Рассмотрим похожие по сложности шрифты. 1. 1. Самым простым шифром является ШИФР С ЗАМЕНОЙ БУКВ ЦИФРАМИ. Каждой букве соответствует число по алфавитному порядку. А-1, B-2, C-3 и т.д. 2. Также можно зашифровывать сообщения с помощью ЦИФРОВОЙ ТАБЛИЦЫ. Её параметры могут быть какими угодно, главное, чтобы получатель и отправитель были в курсе. Пример цифровой таблицы. Рис. 3 Цифровая таблица. Первая цифра в шифре – столбец, вторая – строка или наоборот. Так слово «MIND» можно зашифровать как «33 24 34 14». 3. 3. КНИЖНЫЙ ШИФР
4. 4. ШИФР ЦЕЗАРЯ
(шифр сдвига, сдвиг Цезаря) Еще пример: Шифрование с использованием ключа К=3 . Буква «С» «сдвигается» на три буквы вперёд и становится буквой «Ф». Твёрдый знак, перемещённый на три буквы вперёд, становится буквой «Э», и так далее: Исходный алфавит:А Б В Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
Шифрованный:Г Д Е Ё Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я А Б В
Оригинальный текст: Съешь же ещё этих мягких французских булок, да выпей чаю. Шифрованный текст получается путём замены каждой буквы оригинального текста соответствующей буквой шифрованного алфавита: Фэзыя йз зьи ахлш пвёнлш чугрщцкфнлш дцосн, жг еютзм ъгб. 5. ШИФР С КОДОВЫМ СЛОВОМ
6. 6. ШИФР АТБАШ
7. 7. ШИФР ФРЕНСИСА БЭКОНА
a AAAAA g AABBA m ABABB s BAAAB y BABBA b AAAAB h AABBB n ABBAA t BAABA z BABBB c AAABA i ABAAA o ABBAB u BAABB d AAABB j BBBAA p ABBBA v BBBAB e AABAA k ABAAB q ABBBB w BABAA f AABAB l ABABA r BAAAA x BABAB Сложность дешифрования заключается в определении шифра. Как только он определен, сообщение легко раскладывается по алфавиту. 8. 8. ШИФР БЛЕЗА ВИЖЕНЕРА.
Рис. 4 Шифр Блеза Виженера 9. 9. ШИФР ЛЕСТЕРА ХИЛЛА
10. 10. ШИФР ТРИТЕМИУСА
11. 11. МАСОНСКИЙ ШИФР
12. 12. ШИФР ГРОНСФЕЛЬДА
По своему содержанию этот шифр включает в себя шифр Цезаря и шифр Виженера, однако в шифре Гронсфельда используется числовой ключ. Зашифруем слово “THALAMUS”, используя в качестве ключа число 4123. Вписываем цифры числового ключа по порядку под каждой буквой слова. Цифра под буквой будет указывать на количество позиций, на которые нужно сдвинуть буквы. К примеру вместо Т получится Х и т.д. T H A L A M U S T U V W X Y Z В итоге: THALAMUS = XICOENWV 13. 13. ПОРОСЯЧЬЯ ЛАТЫНЬ
14. 14. КВАДРАТ ПОЛИБИЯ
1 МЕТОД. Вместо каждой буквы в слове используется соответствующая ей буква снизу (A = F, B = G и т.д.). Пример: CIPHER - HOUNIW. Шифров великое множество, и вы так же можете придумать свой собственный шифр, однако изобрести стойкий шифр очень сложно, поскольку наука дешифровки с появлением компьютеров шагнула далеко вперед и любой любительский шифр будет взломан специалистами за очень короткое время. Методы вскрытия одноалфавитных систем (расшифровка)
При своей простоте в реализации одноалфавитные системы шифрования легко уязвимы. И судя по тем рассуждениям, которые были в комментариях, мне бы хотелось прояснить один важный момент, который нужно понимать, прежде чем говорить о языке HTML
и тегах, которые в нем используются. Момент этот заключается в понимании такого важного понятия, как семантика кода
. Давайте в этой заметке попытаемся разобраться с этим вопросом и зачем это все нужно. Что такое семантика кода
? Семантика
(с лингвистической точки зрения) – это смысл, информационное содержание языка или отдельной его единицы. Как мы знаем, структурными единицами языка HTML
являются теги, они и являются теми самими отдельными единицами, которые несут смысл, информационное содержание. Когда перед нами есть какая-то информация, которую нужно представить на веб-странице в Интернете, в первую очередь, мы должны объяснить компьютеру, какая часть этой информации, чем является. Не зная об этом, он просто не сможет правильно отобразить все содержимое. Таким образом, когда мы создаем веб-страницу, с помощью языка HTML
, мы объясняем компьютеру, какой элемент, какую роль должен играть на странице. Мы должны понимать, что содержание каждого элемента веб-страницы должно быть заключено в теги, которые бы соответствовали их логическому и смысловому назначению. Т.е. заголовки в тексте заключались бы в теги h
1-h
6, абзацы в теги p
, списки в теги ul
/ol
(li
) и.т.д. Код, который соответствует этим условиям, называют семантическим
т.е. каждому элементу на веб-странице, соответствует правильное
смысловое значение. А теперь вопрос, можем ли мы заголовок на веб-странице, заключить в тег абзаца? Вывод, который мы с вами должны сделать, исходя из этого, семантика кода и оформление это две разные вещи, которые не нужно путать между собой. Определенное оформление каждому тегу присваивается, но его можно легко изменить,а вот изменить семантическое значение этого тега уже нельзя. Мы можем заключить заголовок в абзац, но при этом теряется семантичность кода и этот текст будет нести совершенно иной смысл. Поэтому, прежде чем заключать элемент в какой-либо тег, желательно подумать, а какую функцию, смысл он несет на странице? Возникает логичный вопрос, а зачем в таком случае вообще нужна семантика кода? Зачем заголовки делать заголовками, абзацы делать абзацами, аббревиатуры делать аббревиатурами и.т.д.? По моему мнению, есть несколько причин, которые помогут вам склониться в сторону семантического кода. Что нам дает семантическая разметка? 1) Информацию о том, как браузеру по умолчанию отображать тот или иной элемент на странице;
Например, мы знаем, что заголовок h
1, если не задавать ему никаких специальных стилей, отображается на странице размером 2em
и жирным шрифтом. Но, по моему мнению это самая не существенная причина. 2) Семантический код лучше читается и воспринимается поисковыми системами;
Считается, что страница, которая имеет семантическую разметку, при прочих равных условиях, будет выдаваться выше в результатах выдачи поисковых систем, чем страница с несемантическим кодом. 2) Код более понятный для человека;
Согласитесь, что разобраться с кодом, где все четко прописано, что эта часть текста является абзацем, эта аббревиатурой, и.т.д. намного легче, чем с кодом, где вся информация идет одной сплошной структурой и не понятно, что хотел сказать автор. 3) Проще получить доступ к элементу и как следствие большая гибкость.
Делая код семантическим, вы сможете намного проще обращаться к этим элементам с помощью специальных средств, которые работают с элементами на веб-страницах, например, языки CSS
, Javascript
и др. Если вы заключите все аббревиатуры на вашей странице в тег abbr
, то в CSS
, для того, чтобы все аббревиатуры на вашей странице стали красными достаточно будет просто прописать. abbr
{color
:red
;} Вместо того, чтобы в HTML
выделять и прописывать это правило к каждой отдельно взятой аббревиатуре. Это всего лишь один пример, которых можно привести массу. По этим причинам нужно понимать, что семантический код просто дает нашему документу больше возможностей. Мы можем применять какие-то теги для улучшения семантики сайта и получать при этом большую функциональность, либо их не применять и не получать эти выгоды. Дело ваше! Вы должны сами для себя принять это решение. 4.1. Основы шифрования
Сущность шифрования методом замены заключается в следующем . Пусть шифруются сообщения на русском языке и замене подлежит каждая буква этих сообщений. Тогда, букве А
исходного алфавита сопоставляется некоторое множество символов (шифрозамен) М А, Б – М Б, …, Я – М Я
. Шифрозамены выбираются таким образом, чтобы любые два множества (М I
и М J
, i ≠ j
) не содержали одинаковых элементов (М I ∩ М J = Ø
). Таблица, приведенная на рис.4.1, является ключом шифра замены. Зная ее, можно осуществить как шифрование, так и расшифрование. Рис.4.1. Таблица шифрозамен При шифровании каждая буква А
открытого сообщения заменяется любым символом из множества М А
. Если в сообщении содержится несколько букв А
, то каждая из них заменяется на любой символ из М А
. За счет этого с помощью одного ключа можно получить различные варианты шифрограммы для одного и того же открытого сообщения. Так как множества М А, М Б, ..., М Я
попарно не пересекаются, то по каждому символу шифрограммы можно однозначно определить, какому множеству он принадлежит, и, следовательно, какую букву открытого сообщения он заменяет. Поэтому расшифрование возможно и открытое сообщение определяется единственным образом. Приведенное выше описание сущности шифров замены относится ко всем их разновидностям за исключением , в которых для зашифрования разных символов исходного алфавита могут использоваться одинаковые шифрозамены (т.е. М I ∩ М J ≠ Ø
, i ≠ j
). Метод замены часто реализуется многими пользователями при работе на компьютере. Если по забывчивости не переключить на клавиатуре набор символов с латиницы на кириллицу, то вместо букв русского алфавита при вводе текста будут печататься буквы латинского алфавита («шифрозамены»). Для записи исходных и зашифрованных сообщений используются строго определенные алфавиты. Алфавиты для записи исходных и зашифрованных сообщений могут отличаться. Символы обоих алфавитов могут быть представлены буквами, их сочетаниями, числами, рисунками, звуками, жестами и т.п. В качестве примера можно привести пляшущих человечков из рассказа А. Конан Дойла () и рукопись рунического письма () из романа Ж. Верна «Путешествие к центру Земли». Шифры замены можно разделить на следующие подклассы
(разновидности). Рис.4.2. Классификация шифров замены I. Регулярные шифры.
Шифрозамены состоят из одинакового количества символов или отделяются друг от друга разделителем (пробелом, точкой, тире и т.п.). Лозунговый шифр.
Для данного шифра построение таблицы шифрозамен основано на лозунге (ключе) – легко запоминаемом слове. Вторая строка таблицы шифрозамен заполняется сначала словом-лозунгом (причем повторяющиеся буквы отбрасываются), а затем остальными буквами, не вошедшими в слово-лозунг, в алфавитном порядке. Например, если выбрано слово-лозунг «ДЯДИНА», то таблица имеет следующий вид. Рис.4.4. Таблица шифрозамен для лозунгового шифра При шифровании исходного сообщения «АБРАМОВ» по приведенному выше ключу шифрограмма будет выглядеть «ДЯПДКМИ». Полибианский квадрат.
Шифр изобретен греческим государственным деятелем, полководцем и историком Полибием (203-120 гг. до н.э.). Применительно к русскому алфавиту и индийским (арабским) цифрам суть шифрования заключалась в следующем. В квадрат 6х6 выписываются буквы (необязательно в алфавитном порядке). Рис.4.5. Таблица шифрозамен для полибианского квадрата Шифруемая буква заменяется на координаты квадрата (строка-столбец), в котором она записана. Например, если исходное сообщение «АБРАМОВ», то шифрограмма – «11 12 36 11 32 34 13». В Древней Греции сообщения передавались с помощью оптического телеграфа (с помощью факелов). Для каждой буквы сообщения вначале поднималось количество факелов, соответствующее номеру строки буквы, а затем номеру столбца. Таблица 4.1. Частота появления букв русского языка в текстах Существуют подобные таблицы для пар букв (биграмм). Например, часто встречаемыми биграммами являются «то», «но», «ст», «по», «ен» и т.д. Другой прием вскрытия шифрограмм основан на исключении возможных сочетаний букв. Например, в текстах (если они написаны без орфографических ошибок) нельзя встретить сочетания «чя», «щы», «ьъ» и т.п. Для усложнения задачи вскрытия шифров однозначной замены еще в древности перед шифрованием из исходных сообщений исключали пробелы и/или гласные буквы. Другим способом, затрудняющим вскрытие, является шифрование биграммами
(парами букв). 4.3. Полиграммные шифры
Полиграммные шифры замены
- это шифры, в которых одна шифрозамена соответствует сразу нескольким символам исходного текста. Биграммный шифр Порты
. Шифр Порты, представленный им в виде таблицы, является первым известным биграммным шифром. Размер его таблицы составлял 20 х 20 ячеек; наверху горизонтально и слева вертикально записывался стандартный алфавит (в нем не было букв J, К, U, W, X и Z). В ячейках таблицы могли быть записаны любые числа, буквы или символы - сам Джованни Порта пользовался символами - при условии, что содержимое ни одной из ячеек не повторялось. Применительно к русскому языку таблица шифрозамен может выглядеть следующим образом. Рис.4.10. Таблица шифрозамен для шифра Порты Шифрование выполняется парами букв исходного сообщения. Первая буква пары указывает на строку шифрозамены, вторая - на столбец. В случае нечетного количества букв в исходном сообщении к нему добавляется вспомогательный символ («пустой знак»). Например, исходное сообщение «АБ РА МО В», зашифрованное – «002 466 355 093». В качестве вспомогательного символа использована буква «Я». Шифр Playfair (англ. «Честная игра»).
В начале 1850-х гг. Чарлз Уитстон придумал так называемый «прямоугольный шифр». Леон Плейфер, близкий друг Уитстона, рассказал об этом шифре во время официального обеда в 1854 г. министру внутренних дел лорду Пальмерстону и принцу Альберту. А поскольку Плейфер был хорошо известен в военных и дипломатических кругах, то за творением Уитстона навечно закрепилось название «шифр Плейфера». Данный шифр стал первым буквенным биграммным шифром (в биграммной таблице Порты использовались символы, а не буквы). Он был предназначен для обеспечения секретности телеграфной связи и применялся британскими войсками в Англо-бурской и Первой мировой войнах. Им пользовалась также австралийская служба береговой охраны островов во время Второй мировой войны. Шифр предусматривает шифрование пар символов (биграмм). Таким образом, этот шифр более устойчив к взлому по сравнению с шифром простой замены, так как затрудняется частотный анализ. Он может быть проведен, но не для 26 возможных символов (латинский алфавит), а для 26 х 26 = 676 возможных биграмм. Анализ частоты биграмм возможен, но является значительно более трудным и требует намного большего объема зашифрованного текста. Для шифрования сообщения необходимо разбить его на биграммы (группы из двух символов), при этом, если в биграмме встретятся два одинаковых символа, то между ними добавляется заранее оговоренный вспомогательный символ (в оригинале – X
, для русского алфавита - Я
). Например, «зашифрованное сообщение» становится «за ши фр ов ан но ес оЯ
об ще ни еЯ
». Для формирования ключевой таблицы выбирается лозунг и далее она заполняется по правилам шифрующей системы Трисемуса. Например, для лозунга «ДЯДИНА» ключевая таблица выглядит следующим образом. Рис.4.11. Ключевая таблица для шифра Playfair Затем, руководствуясь следующими правилами, выполняется зашифровывание пар символов исходного текста: 1. Если символы биграммы исходного текста встречаются в одной строке, то эти символы замещаются на символы, расположенные в ближайших столбцах справа от соответствующих символов. Если символ является последним в строке, то он заменяется на первый символ этой же строки. 2. Если символы биграммы исходного текста встречаются в одном столбце, то они преобразуются в символы того же столбца, находящимися непосредственно под ними. Если символ является нижним в столбце, то он заменяется на первый символ этого же столбца. 3. Если символы биграммы исходного текста находятся в разных столбцах и разных строках, то они заменяются на символы, находящиеся в тех же строках, но соответствующие другим углам прямоугольника. Пример шифрования. Биграмма «за» формирует прямоугольник – заменяется на «жб»; Биграмма «ши» находятся в одном столбце – заменяется на «юе»; Биграмма «фр» находятся в одной строке – заменяется на «хс»; Биграмма «ов» формирует прямоугольник – заменяется на «йж»; Биграмма «ан» находятся в одной строке – заменяется на «ба»; Биграмма «но» формирует прямоугольник – заменяется на «ам»; Биграмма «ес» формирует прямоугольник – заменяется на «гт»; Биграмма «оя» формирует прямоугольник – заменяется на «ка»; Биграмма «об» формирует прямоугольник – заменяется на «па»; Биграмма «ще» формирует прямоугольник – заменяется на «шё»; Биграмма «ни» формирует прямоугольник – заменяется на «ан»; Биграмма «ея» формирует прямоугольник – заменяется на «ги». Шифрограмма – «жб юе хс йж ба ам гт ка па шё ан ги». Для расшифровки необходимо использовать инверсию этих правил, откидывая символы Я
(или Х
), если они не несут смысла в исходном сообщении. Он состоял из двух дисков – внешнего неподвижного и внутреннего подвижного дисков, на которые были нанесены буквы алфавита. Процесс шифрования заключался в нахождении буквы открытого текста на внешнем диске и замене ее на букву с внутреннего диска, стоящую под ней. После этого внутренний диск сдвигался на одну позицию и шифрование второй буквы производилось уже по новому шифралфавиту. Ключом данного шифра являлся порядок расположения букв на дисках и начальное положение внутреннего диска относительно внешнего. Таблица Трисемуса.
Одним из шифров, придуманных немецким аббатом Трисемусом, стал многоалфавитный шифр, основанный на так называемой «таблице Трисемуса» - таблице со стороной равной n
, где n
– количество символов в алфавите. В первой строке матрицы записываются буквы в порядке их очередности в алфавите, во второй – та же последовательность букв, но с циклическим сдвигом на одну позицию влево, в третьей – с циклическим сдвигом на две позиции влево и т.д. Рис.4.17. Таблица Трисемуса Первая строка является одновременно и алфавитом для букв открытого текста. Первая буква текста шифруется по первой строке, вторая буква по второй и так далее. После использования последней строки вновь возвращаются к первой. Так сообщение «АБРАМОВ» приобретет вид «АВТГРУЗ». Система шифрования Виженера.
В 1586 г. французский дипломат Блез Виженер представил перед комиссией Генриха III описание простого, но довольно стойкого шифра, в основе которого лежит таблица Трисемуса. Перед шифрованием выбирается ключ из символов алфавита. Сама процедура шифрования заключается в следующем. По i-ому символу открытого сообщения в первой строке определяется столбец, а по i-ому символу ключа в крайнем левом столбце – строка. На пересечении строки и столбца будет находиться i-ый символ, помещаемый в шифрограмму. Если длина ключа меньше сообщения, то он используется повторно. Например, исходное сообщение «АБРАМОВ», ключ – «ДЯДИНА», шифрограмма – «ДАФИЪОЁ». Справедливости ради, следует отметить, что авторство данного шифра принадлежит итальянцу Джованни Батиста Беллазо, который описал его в 1553 г. История «проигнорировала важный факт и назвала шифр именем Виженера, несмотря на то, что он ничего не сделал для его создания» . Беллазо предложил называть секретное слово или фразу паролем
(ит. password; фр. parole - слово). В 1863 г. Фридрих Касиски опубликовал алгоритм атаки на этот шифр, хотя известны случаи его взлома шифра некоторыми опытными криптоаналитиками и ранее. В частности, в 1854 г. шифр был взломан изобретателем первой аналитической вычислительной машины Чарльзом Бэббиджем, хотя этот факт стал известен только в XX в., когда группа ученых разбирала вычисления и личные заметки Бэббиджа . Несмотря на это шифр Виженера имел репутацию исключительно стойкого к «ручному» взлому еще долгое время. Так, известный писатель и математик Чарльз Лютвидж Доджсон (Льюис Кэрролл) в своей статье «Алфавитный шифр», опубликованной в детском журнале в 1868 г., назвал шифр Виженера невзламываемым. В 1917 г. научно-популярный журнал «Scientific American» также отозвался о шифре Виженера, как о неподдающемся взлому . Роторные машины.
Идеи Альберти и Беллазо использовались при создании электромеханических роторных машин первой половины ХХ века. Некоторые из них использовались в разных странах вплоть до 1980-х годов. В большинстве из них использовались роторы (механические колеса), взаимное расположение которых определяло текущий алфавит шифрозамен, используемый для выполнения подстановки. Наиболее известной из роторных машин является немецкая машина времен Второй мировой войны «Энигма» . Выходные штыри одного ротора соединены с входными штырями следующего ротора и при нажатии символа исходного сообщения на клавиатуре замыкали электрическую цепь, в результате чего загоралась лампочка с символом шифрозамены. Рис.4.19. Роторная система Энигмы [www.cryptomuseum.com ] Шифрующее действие «Энигмы» показано для двух последовательно нажатых клавиш - ток течёт через роторы, «отражается» от рефлектора, затем снова через роторы. Рис.4.20. Схема шифрования Примечание. Серыми линиями показаны другие возможные электрические цепи внутри каждого ротора. Буква A
шифруется по-разному при последовательных нажатиях одной клавиши, сначала в G
, затем в C
. Сигнал идет по другому маршруту за счёт поворота одного из роторов после нажатия предыдущей буквы исходного сообщения. 3. Дайте характеристику разновидностям шифров замены. Целью
дан разр явл: Сформировать
наиб общ принц созд сем кода Показ
в общем виде на примерах его возможности Обнаруж
пути возм. Статья 100 000-го словаря Созд
пробн сист. Мы оперир словарем в объеме
около 400 слов и выр-ний. И наз отвеч на
вопр к тексту обземом в страницу не
представл сложности. Подобн
система мб постр лингвистически за 2-3
месяца, за 2 мес отлажена в прогр виде.
При этом можно искл тот же самый текст,
как на РЯ, так и на АЯ При
всей искуств текста, а он практически
содержит избыт инф-цию в реальн текстах
такой инф-ции не бывает. Данная работа
- аналог сист груб понимания при одном
условии: если мы решим, что такое машинное
понимание? Принципы
хранятся в двух основных моментах: Прежде
всего целостн картины мира … на отдельные
части множ-вом. Пр0-й. Именно поэтому
ученье часто ив о «мозаичном» знании.
Так, в моногр фр иссл-я А. Моля целый
раздел посвящен мозаичной культуре и
ср-вам масс коммуникации, созд именно
мозаичн картины мира Чаще
всего эти Пр0-и несвяз др с другом и в
силу отсуств общ сист термин-ии. Эта
разобщ мешает формализ даже именому
знание о мире. Это происходит из-за того,
что в рамках Пр0 вновь сталк с делен на
подобл знания. При
разг о зания и попытки их форм-ть не
учит-ся сама изм приращ знаний за счет
их можериз-я. Знания приобр-ся лишь за
счет напол нав игф, а не за счет лог
вывода новых знаний на базе старых.
Между тем ребенок, освоив мир, моделирует
и модернизирует. Причины
создания такой научн сист-м соверш
разнопл. Одна из них - это отсуствие
мат аппарата и эмпиризм и диктат практики.
Само отсутсв мат аппарата мб и неведения
что этот апп нах-ся в твоих руках, но ты
его не видишь. Смысл
относится к тем загадочным явлениям,
которые считаются как бы общеизвестными,
поскольку постоянно фигурируют как в
научном, так и обыденном общении. На
самом деле он не только не имеет
сколько-нибудь строгого общепринятого
определения, но и на описательном уровне
существует большой разброс суждений о
том, что это такое.
Иногда допускается,
что смысл принадлежит к тем наиболее
общим категориям, которые не подлежат
определению и должны восприниматься
как некоторая данность.
В настоящее
время в связи с необходимостью решения
целого ряда актуальных задач как
теоретического, так и прикладного
характера, где понятие смысла играет
ключевое значение, требуются определенные
уточнения данного понятия. Онтология
смысла приобретает особую значимость
в связи с теми изменениями в понимании
объекта, предмета и задач лингвистики,
которые уже произошли и продолжают
происходить в настоящее время. Если в
период, когда доминировала абсолютизация
языка как самодостаточной автономной
сущности, смысл часто выступал лишь как
некоторое факультативное явление,
находящееся на периферии интересов
исследователей, то при обращении к речи,
тексту, дискурсу смысл начинает
фигурировать как одна из наиболее
фундаментальных категорий. С.А.Васильев
различает предметный смысл и текстовый.
Предметный смысл связывается им с
механизмом вычленения, осознания
предметов реальной действительности.
В связи с этим основу смысла, по мнению
автора, составляет способность
устанавливать тождество и различие."Вещи
неразличимы, если имеют для человека
равный смысл, как неразличимы штампованные
экземпляры одной и той же детали"
(Васильев 1988, 96). С.А.Васильев
выделяет несколько составляющих смысла.
Одной из таких составляющих является
предметная объективация человеческого
опыта в виде знания о данном предмете.
Но оно, по мнению автора, образует лишь
наиболее общую составляющую смысла,
интерсубъектную по своему источнику,
имеющую общечеловеческую ценность.
Помимо этого смысл содержит и такие
компоненты, которые выражают жизненные
установки ее носителей, их особые
отношения к предметному миру. Эти две
составляющие смысла лежат в основе
межиндивидуального общения, а потому
откладываются в их сознании и фиксируются
как устойчивые, повторяющиеся компоненты,
постоянно воспроизводимые в речи. Кроме
того, в состав смысла входит индивидуальный
опыт, глубоко личностные отношения
индивида к предмету и возникающие отсюда
ожидания, привязанности, эмоции, памятные
ассоциации, которые выделяют данный
предмет из множества похожих на него. Все
это составляет, по терминологии автора,
"смысл-ценность", который имеет
отношение не только к предметному миру,
но реализуется и на уровне текста,
составляя один из его смысловых уровней.
Другой уровень текста составляет
"смысл-сообщение" т.е. то, что хотел
сказать автор. Все
это позволяет автору сделать вывод о
том, что заключенный в тексте
"смысл-сообщение" является
специфическим свойством, отличающим
его от всех прочих предметов, которые
текстами не являются, а "смысл-ценность",
который текст приобретает вследствие
включенности его в систему жизнедеятельности
человеческого общества, наоборот,
сближает его с другими предметами,
делает его элементом того предметного
универсума, в котором разворачивается
вся человеческая жизнь. Характеризуя
"смысл-сообщение", С.А.Васильев
обращает внимание на одну очень
существенную его особенность. Он задается
вопросом: за счет чего смысл целого
высказывания оказывается всегда больше
суммы значений, образующих его слов? В
связи с этим он анализирует фрагмент
романа М.Ю.Лермонтова "Герой нашего
времени", в частности, слова Максимыча,
характеризующие поведение Печорина:"...ставни
стукнут, он вздрогнет и побледнеет; а
при мне на кабана ходил один на один..."
Автор отмечает, что приведенные слова
сами по себе не воссоздают смысл поведения
героя. Он считает, что здесь "говорит"
само поведение, сам поступок: пугливость,
храбрость... Как бы мы эти слова не
сочетали, мы никак не получим значения
пугливости, храбрости. Союз "а"
здесь противопоставляет смысл не двух
частей фразы, а двух способов поведения,
которое мы понимаем на основе нашего
индивидуального и усвоенного коллективного
опыта. В результате автор делает
чрезвычайно важный для понимания природы
смысла вывод: "Здесь происходит
использование невербальных средств в
вербальном тексте"(Васильев 1988, 98).
Это во-первых, свидетельствует об
экстралингвистическом характере смысла,
во-вторых, о том, что он является внешним
по отношению к тексту, поскольку связан
с актуализацией прошлого опыта, знания,
оценочно-эмоциональных компонентов
сознания личности. Кроме того, отсюда
можно сделать вывод и о том, что смысл
не содержится непосредственно в тексте,
а является производным от процесса
понимания, в котором он собственно и
возникает как некоторая субстанция.
Этот вывод возникает как объективное
следствие, вытекающее из рассуждений
автора, хотя оно и вступает в противоречие
с некоторыми другими его положениями. с указанием класса. Название статьи становится заголовком, содержание становится параграфом, а выделенный жирным шрифтом текст становится тегом .
,
,
, и так далее, но к другим элементам интерфейса.
Но...
Например слово «TOWN » можно записать как «20 15 23 14», но особой секретности и сложности в дешифровке это не вызовет.
В таком шифре ключом является некая книга, имеющаяся и у отправителя и у получателя. В шифре обозначается страница книги и строка, первое слово которой и является разгадкой. Дешифровка невозможна, если книги у отправителя и корреспондента разных годов издания и выпуска. Книги обязательно должны быть идентичными.
Известный шифр. Сутью данного шифра является замена одной буквы другой, находящейся на некоторое постоянное число позиций левее или правее от неё в алфавите. Гай Юлий Цезарь использовал этот способ шифрования при переписке со своими генералами для защиты военных сообщений. Этот шифр довольно легко взламывается, поэтому используется редко. Сдвиг на 4. A = E, B= F, C=G, D=H и т.д.
Пример шифра Цезаря: зашифруем слово « DEDUCTION » .
Получаем: GHGXFWLRQ . (сдвиг на 3)
Еще один простой способ как в шифровании, так и в расшифровке. Используется кодовое слово (любое слово без повторяющихся букв). Данное слово вставляется впереди алфавита и остальные буквы по порядку дописываются, исключая те, которые уже есть в кодовом слове. Пример: кодовое слово – NOTEPAD.
Исходный:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
Замена:N O T E P A D B C F G H I J K L M Q R S U V W X Y Z
Один из наиболее простых способов шифрования. Первая буква алфавита заменяется на последнюю, вторая – на предпоследнюю и т.д.
Пример: « SCIENCE » = HXRVMXV
Один из наиболее простых методов шифрования. Для шифрования используется алфавит шифра Бэкона: каждая буква слова заменяется группой из пяти букв «А» или «B» (двоичный код).
Существует несколько способов кодирования.
Также можно зашифровать предложение с помощью двоичного кода. Определяются параметры (например, «А» - от A до L, «В» - от L до Z). Таким образом, BAABAAAAABAAAABABABB означает TheScience of Deduction ! Этот способ более сложен и утомителен, но намного надежнее алфавитного варианта.
Этот шифр использовался конфедератами во время Гражданской войны. Шифр состоит из 26 шифров Цезаря с различными значениями сдвига (26 букв лат.алфавита). Для зашифровывания может использоваться tabula recta (квадрат Виженера). Изначально выбирается слово-ключ и исходный текст. Слово ключ записывается циклически, пока не заполнит всю длину исходного текста. Далее по таблице буквы ключа и исходного текста пересекаются в таблице и образуют зашифрованный текст.
Основан на линейной алгебре. Был изобретен в 1929 году.
В таком шифре каждой букве соответствует число (A = 0, B =1 и т.д.). Блок из n-букв рассматривается как n-мерный вектор и умножается на (n х n) матрицу по mod 26. Матрица и является ключом шифра. Для возможности расшифровки она должна быть обратима в Z26n.
Для того, чтобы расшифровать сообщение, необходимо обратить зашифрованный текст обратно в вектор и умножить на обратную матрицу ключа. Для подробной информации – Википедия в помощь.
Усовершенствованный шифр Цезаря. При расшифровке легче всего пользоваться формулой:
L= (m+k) modN , L-номер зашифрованной буквы в алфавите, m-порядковый номер буквы шифруемого текста в алфавите, k-число сдвига, N-количество букв в алфавите.
Является частным случаем аффинного шифра.

4 1 2 3 4 1 2 3
0 1 2 3 4
Чаще используется как детская забава, особой трудности в дешифровке не вызывает. Обязательно употребление английского языка, латынь здесь ни при чем.
В словах, начинающихся с согласных букв, эти согласные перемещаются назад и добавляется “суффикс” ay. Пример: question = estionquay. Если же слово начинается с гласной, то к концу просто добавляется ay, way, yay или hay (пример: a dog = aay ogday).
В русском языке такой метод тоже используется. Называют его по-разному: “синий язык”, “солёный язык”, “белый язык”, “фиолетовый язык”. Таким образом, в Синем языке после слога, содержащего гласную, добавляется слог с этой же гласной, но с добавлением согласной “с” (т.к. язык синий). Пример:Информация поступает в ядра таламуса = Инсифорсомасацисияся поссотусупасаетсе в ядсяраса тасаласамусусаса.
Довольно увлекательный вариант.
Подобие цифровой таблицы. Существует несколько методов использования квадрата Полибия. Пример квадрата Полибия: составляем таблицу 5х5 (6х6 в зависимости от количества букв в алфавите).
2 МЕТОД. Указываются соответствующие каждой букве цифры из таблицы. Первой пишется цифра по горизонтали, второй - по вертикали. (A = 11, B = 21…). Пример: CIPHER = 31 42 53 32 51 24
3 МЕТОД. Основываясь на предыдущий метод, запишем полученный код слитно. 314253325124. Делаем сдвиг влево на одну позицию. 142533251243. Снова разделяем код попарно.14 25 33 25 12 43. В итоге получаем шифр. Пары цифр соответствуют букве в таблице: QWNWFO.
Определим количество различных систем в аффинной системе. Каждый ключ полностью определен парой целых чисел a и b, задающих отображение ax+b. Для а существует j(n) возможных значений, где j(n) - функция Эйлера, возвращающая количество взаимно простых чисел с n, и n значений для b, которые могут быть использованы независимо от a, за исключением тождественного отображения (a=1 b=0), которое мы рассматривать не будем.
Таким образом получается j(n)*n-1 возможных значений, что не так уж и много: при n=33 в качестве a могут быть 20 значений(1, 2, 4, 5, 7, 8, 10, 13, 14, 16, 17, 19, 20, 23, 25, 26, 28, 29, 31, 32), тогда общее число ключей равно 20*33-1=659. Перебор такого количества ключей не составит труда при использовании компьютера.
Но существуют методы упрощающие этот поиск и которые могут быть использованы при анализе более сложных шифров.
Частотный анализ
Одним из таких методов является частотный анализ. Распределение букв в криптотексте сравнивается с распределением букв в алфавите исходного сообщения. Буквы с наибольшей частотой в криптотексте заменяются на букву с наибольшей частотой из алфавита. Вероятность успешного вскрытия повышается с увеличением длины криптотекста.
Существуют множество различных таблиц о распределении букв в том или ином языке, но ни одна из них не содержит окончательной информации - даже порядок букв может отличаться в различных таблицах. Распределение букв очень сильно зависит от типа теста: проза, разговорный язык, технический язык и т.п. В методических указаниях к лабораторной работе приведены частотные характеристики для различных языков, из которых ясно, что буквы буквы I, N, S, E, A (И, Н, С, Е, А) появляются в высокочастотном классе каждого языка.
Простейшая защита против атак, основанных на подсчете частот, обеспечивается в системе омофонов (HOMOPHONES) - однозвучных подстановочных шифров, в которых один символ открытого текста отображается на несколько символов шифротекста, их число пропорционально частоте появления буквы. Шифруя букву исходного сообщения, мы выбираем случайно одну из ее замен. Следовательно простой подсчет частот ничего не дает криптоаналитику. Однако доступна информация о распределении пар и троек букв в различных естественных языках.
А почем нет? Конечно, можем. Многие скажут, но ведь при этом мы теряем оформление, которое имеют заголовки h
1-h
6. Но, на самом деле, оформление здесь никакой роли не играет. С помощью стилей CSS
, мы можем присвоить любому абзацу точно такое же оформление, которое было у элемента h
1-h
6.А
Б
...
Я
М А
М Б
...
М Я

А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
Д
Я
И
Н
А
Б
В
Г
Е
Ё
Ж
З
Й
К
Л
М
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
1
2
3
4
5
6
1
А
Б
В
Г
Д
Е
2
Ё
Ж
З
И
Й
К
3
Л
М
Н
О
П
Р
4
С
Т
У
Ф
Х
Ц
5
Ч
Ш
Щ
Ъ
Ы
Ь
6
Э
Ю
Я
-
-
-
№ п/п
Буква
Частота, %
№ п/п
Буква
Частота, %
1
О
10.97
18
Ь
1.74
2
Е
8.45
19
Г
1.70
3
А
8.01
20
З
1.65
4
И
7.35
21
Б
1.59
5
Н
6.70
22
Ч
1.44
6
Т
6.26
23
Й
1.21
7
С
5.47
24
Х
0.97
8
Р
4.73
25
Ж
0.94
9
В
4.54
26
Ш
0.73
10
Л
4.40
27
Ю
0.64
11
К
3.49
28
Ц
0.48
12
М
3.21
29
Щ
0.36
13
Д
2.98
30
Э
0.32
14
П
2.81
31
Ф
0.26
15
У
2.62
32
Ъ
0.04
16
Я
2.01
33
Ё
0.04
17
Ы
1.90
А
Б
В
Г
Д
Е
(Ё)
Ж
З
И
(Й)
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
001
002
003
004
005
006
007
008
009
010
011
012
013
014
015
016
017
018
019
020
021
022
023
024
025
026
027
028
029
030
031
Б
032
033
034
035
036
037
038
039
040
041
042
043
044
045
046
047
048
049
050
051
052
053
054
055
056
057
058
059
060
061
062
В
063
064
065
066
067
068
069
070
071
072
073
074
075
076
077
078
079
080
081
082
083
084
085
086
087
088
089
090
091
092
093
Г
094
095
096
097
098
099
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
Д
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
Е (Ё)
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
Ж
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
З
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
И (Й)
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
К
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
Л
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
М
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
Н
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
О
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
П
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
Р
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
С
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
Т
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
У
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
Ф
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
Х
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
Ц
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
Ч
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
Ш
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
Щ
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
Ъ
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
Ы
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
Ь
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
Э
869
870
871
872
873
874
875
876
877
878
879
880
881
882
883
884
885
886
887
888
889
890
891
892
893
894
895
896
897
898
899
Ю
900
901
902
903
904
905
906
907
908
909
910
911
912
913
914
915
916
917
918
919
920
921
922
923
924
925
926
927
928
929
930
Я
931
932
933
934
935
936
937
938
939
940
941
942
943
944
945
946
947
948
949
950
951
952
953
954
955
956
957
958
959
960
961
Д
Я
И
Н
А
Б
В
Г
Е
Ё
Ж
З
Й
К
Л
М
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
-
1
2
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ш
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Щ
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Ъ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ы
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ь
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Э
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Ю
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Я
А
Б
В
Г
Д
Е
Ё
Ж
З
И
Й
К
Л
М
Н
О
П
Р
С
Т
У
Ф
Х
Ц
Ч
Ш
Щ
Ъ
Ы
Ь
Э
Ю


Семантический код. Его цели. Предназначение. Принцип построения. Возможности.
Предназначение семантического кода. Термин «смысл».

Вредоносное ПО (malware) - это назойливые или опасные программы,...

Лучшие программы для восстановления данных с любых носителей информации....

Здравствуйте.Одна из самых распространенных причин, по которым тормозит...